使用Python以及工具包进行简单的验证码识别
<
div id=”content” contentScore=”981″>使用Python以及工具包进行简单的验证码识别,直接开始。
原始图像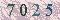
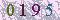
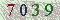
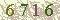
Step 1 打开图像吧。
im = Image.open(‘temp1.jpg’)
Step 2 把彩色图像转化为灰度图像。彩色图像转化为灰度图像的方法很多,这里采用RBG转化到HSI彩色空间,采用I分量。
imgry = im.convert(‘L’)
灰度看起来是这样的
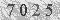
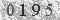
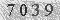
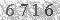
Step 3 需要把图像中的噪声去除掉。这里的图像比较简单,直接阈值化就行了。我们把大于阈值threshold的像素置为1,其他的置为0。对此,先生成一张查找表,映射过程让库函数帮我们做。
threshold = 140
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
阈值为什么是140呢?试出来的,或者参考直方图。
映射过程为
out = imgry.point(table,’1′)
此时图像看起来是这样的
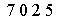
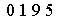
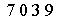
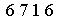
Step 4 把图片中的字符转化为文本。采用pytesser 中的image_to_string函数
text = image_to_string(out)
#对于识别成字母的 采用该表进行修正
rep={‘O’:’0′,
‘I’:’1′,’L’:’1′,
‘Z’:’2′,
‘S’:’8′
};
text = text.replace(r,rep[r])
<
div>好了,text中为最终结果。
0195
7039
6716
import ImageEnhance
import ImageFilter
import sys
from pytesser import *
threshold = 140
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
#对于识别成字母的 采用该表进行修正
rep={‘O’:’0′,
‘I’:’1′,’L’:’1′,
‘Z’:’2′,
‘S’:’8′
};
#打开图片
im = Image.open(name)
#转化到亮度
imgry = im.convert(‘L’)
imgry.save(‘g’+name)
#二值化
out = imgry.point(table,’1′)
out.save(‘b’+name)
#识别
text = image_to_string(out)
#识别对吗
text = text.strip()
text = text.upper();
text = text.replace(r,rep[r])
print text
return text
getverify1(‘v1.jpg’)
getverify1(‘v2.jpg’)
getverify1(‘v3.jpg’)
getverify1(‘v4.jpg’)
<
div contentScore=”411″>
下载在Linux公社的1号FTP服务器里,下载地址:
FTP地址:ftp://www.linuxidc.com
用户名:www.linuxidc.com
密码:www.muu.cc
在 2013年LinuxIDC.com1月使用Python以及工具包进行简单的验证码识别
About The Author
bjmayor
程序员,码农,php,python,ios,android,go,产品经理,创业。