Docker安装ELK并实现JSON格式日志分析
ELK是什么
ELK是elastic公司提供的一套完整的日志收集以及前端展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash和Kibana。
其中Logstash负责对日志进行处理,如日志的过滤、日志的格式化等;ElasticSearch具有强大的文本搜索能力,因此作为日志的存储容器;而Kibana负责前端的展示。
ELK搭建架构如下图: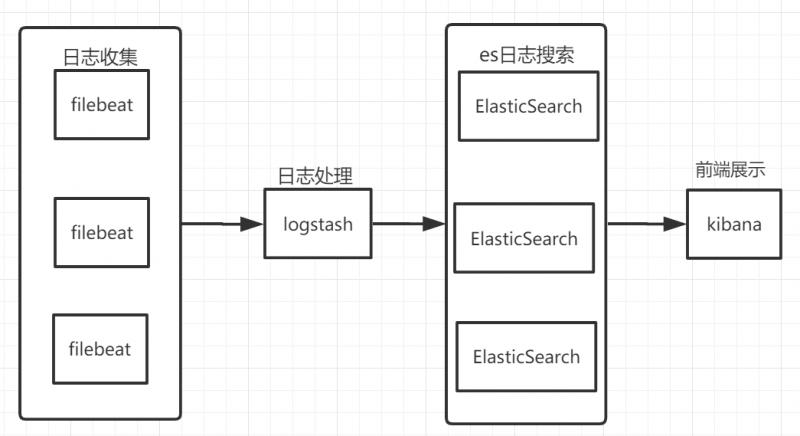
加入了filebeat用于从不同的客户端收集日志,然后传递到Logstash统一处理。
ELK的搭建
因为ELK是三个产品,可以选择依次安装这三个产品。
这里选择使用Docker安装ELk。
Docker安装ELk也可以选择分别下载这三个产品的镜像并运行,但是本次使用直接下载elk的三合一镜像来安装。
因此首先要保证已经有了Docker的运行环境,Docker运行环境的搭建请查看:https://blog.csdn.net/qq1311256696/article/details/85277220
拉取镜像
有了Docker环境之后,在服务器运行命令:
docker pull sebp/elk
这个命令是在从Docker仓库下载elk三合一的镜像,总大小为2个多G,如果发现下载速度过慢,可以将Docker仓库源地址替换为国内源地址。
下载完成之后,查看镜像:
docker images

Logstash配置
在/usr/config/logstash目录下新建beats-input.conf,用于日志的输入:
input {
beats {
port => 5044
}
}新建output.conf,用于日志由Logstash到ElasticSearch的输出:
output {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "%{[@metadata][beat]}"
}
}其中的index为输出到ElasticSearch后的index。
运行容器
有了镜像之后直接启动即可:
docker run -d -p 5044:5044 -p 5601:5601 -p 9203:9200 -p 9303:9300 -v /var/data/elk:/var/lib/elasticsearch -v /usr/config/logstash:/etc/logstash/conf.d --name=elk sebp/elk
-d的意思是后台运行容器;
-p的意思是宿主机端口:容器端口,即将容器中使用的端口映射到宿主机上的某个端口,ElasticSearch的默认端口是9200和9300,由于我的机器上已经运行了3台ElasticSearch实例,因此此处将映射端口进行了修改;
-v的意思是宿主机的文件|文件夹:容器的文件|文件夹,此处将容器中elasticsearch 的数据挂载到宿主机的/var/data/elk上,以防容器重启后数据的丢失;并且将logstash的配置文件挂载到宿主机的/usr/config/logstash目录。
–name的意思是给容器命名,命名是为了之后操作容器更加方便。
如果你之前搭建过ElasticSearch的话,会发现搭建的过程中有各种错误,但是使用docker搭建elk的过程中并没有出现那些错误。
运行后查看容器:
docker ps

查看容器日志:
docker logs -f elk
进入容器:
docker exec -it elk /bin/bash
修改配置后重启容器:
docker restart elk
查看kinaba
浏览器输入http://my_host:5601/
即可看到kinaba界面。此时ElasticSearch中还没有数据,需要安装Filebeat采集数据到elk中。
Filebeat搭建
Filebeat用于采集数据并上报到Logstash或者ElasticSearch,在需要采集日志的服务器上下载Filebeat并解压即可使用
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.1-linux-x86_64.tar.gz
tar -zxvf filebeat-6.2.1-linux-x86_64.tar.gz
修改配置文件
进入filebeat,修改filebeat.yml。
filebeat.prospectors:
- type: log
#需要设置为true配置才能生效
enabled: true
path:
#配置需要采集的日志路径
- /var/log/*.log
#可以打一个tag以后分类使用
tag: ["my_tag"]
#对应ElasticSearch的type
document_type: my_type
setup.kibana:
#此处为kibana的ip及端口,即kibana:5601
host: ""
output.logstash:
#此处为logstash的ip及端口,即logstash:5044
host: [""]
#需要设置为true,否则不生效
enabled: true
#如果想直接从Filebeat采集数据到ElasticSearch,则可以配置output.elasticsearch的相关配置运行Filebeat
运行:
./filebeat -e -c filebeat.yml -d "publish"
此时可以看到Filebeat会将配置的path下的log发送到Logstash;然后在elk中,Logstash处理完数据之后就会发送到ElasticSearch。但我们想做的是通过elk进行数据分析,因此导入到ElasticSearch的数据必须是JSON格式的。
这是之前我的单条日志的格式:
2019-10-22 10:44:03.441 INFO rmjk.interceptors.IPInterceptor Line:248 - {"clientType":"1","deCode":"0fbd93a286533d071","eaType":2,"eaid":191970823383420928,"ip":"xx.xx.xx.xx","model":"HONOR STF-AL10","osType":"9","path":"/applicationEnter","result":5,"session":"ef0a5c4bca424194b29e2ff31632ee5c","timestamp":1571712242326,"uid":"130605789659402240","v":"2.2.4"}导入之后不好分析,之后又想到使用Logstash的filter中的grok来处理日志使之变成JSON格式之后再导入到ElasticSearch中,但是由于我的日志中的参数是不固定的,发现难度太大了,于是转而使用Logback,将日志直接格式化成JSON之后,再由Filebeat发送。
Logback配置
我的项目是Spring Boot,在项目中加入依赖:
net.logstash.logback
logstash-logback-encoder
5.2
然后在项目中的resource目录下加入logback.xml:
service
${LOG_PATH}/${APPDIR}/log_error.log
${LOG_PATH}/${APPDIR}/error/log-error-%d{yyyy-MM-dd}.%i.log
2MB
true
%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n
utf-8
error
ACCEPT
DENY
${LOG_PATH}/${APPDIR}/log_warn.log
${LOG_PATH}/${APPDIR}/warn/log-warn-%d{yyyy-MM-dd}.%i.log
2MB
true
%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n
utf-8
warn
ACCEPT
DENY
${LOG_PATH}/${APPDIR}/log_info.log
${LOG_PATH}/${APPDIR}/info/log-info-%d{yyyy-MM-dd}.%i.log
2MB
true
%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n
utf-8
info
ACCEPT
DENY
${LOG_PATH}/${APPDIR}/log_IPInterceptor.log
${LOG_PATH}/${APPDIR}/log_IPInterceptor.%d{yyyy-MM-dd}.log
10
\u2028
{
"timestamp":"%date{ISO8601}",
"uid":"%mdc{uid}",
"requestIp":"%mdc{ip}",
"id":"%mdc{id}",
"clientType":"%mdc{clientType}",
"v":"%mdc{v}",
"deCode":"%mdc{deCode}",
"dataId":"%mdc{dataId}",
"dataType":"%mdc{dataType}",
"vid":"%mdc{vid}",
"did":"%mdc{did}",
"cid":"%mdc{cid}",
"tagId":"%mdc{tagId}"
}
${CONSOLE_LOG_PATTERN}
utf-8
debug
其中的关键为:
在需要打印的文件中引入slf4j:
private static final Logger LOG = LoggerFactory.getLogger("IPInterceptor");MDC中放入需要打印的信息:
MDC.put("ip", ipAddress);
MDC.put("path", servletPath);
MDC.put("uid", paramMap.get("uid") == null ? "" : paramMap.get("uid").toString());此时如果使用了LOG.info("msg")的话,打印的内容会输入到日志的message中,日志格式如下:
修改Logstash配置
修改/usr/config/logstash目录下的beats-input.conf:
input {
beats {
port => 5044
codec => "json"
}
}只加了一句codec => "json",但是Logstash会按照JSON格式来解析输入的内容。
因为修改了配置,重启elk:
docker restart elk
这样,当我们的日志生成完毕之后,使用Filebeat导入到elk中,就可以通过Kibana来进行日志分析了。
转评赞就是最大的鼓励