如何使用 Kafka、MongoDB 和 Maxwell's Daemon 构建 SQL 数据库的审计系统
本文要点
- 审计日志系统有很多应用场景,而不仅仅是存储用于审计目的的数据。除了合规性和安全性的目的之外,它还能够被市场营销团队使用,以便于锁定目标用户,也可以用来生成重要的告警。
- 数据库内置的审计日志功能可能并不够用,要处理所有的用户场景,它肯定不是理想的方式。
-
目前,有很多的开源工具,如 Maxwell’s Daemons
、 Debezium
,它们能够以最少的基础设施和时间需求支持这些需求。 -
Maxwell’s daemons 能够读取 SQL bin 日志并发送事件到各种生产者,比如 Kafka
、 Amazon Kinesis
、 SQS
、 Rabbit MQ
等。 - SQL 数据库生成的 bin 日志必须是基于 ROW 的格式,这样才能使整个环境运行起来。
假设你正在使用关系型数据来维护事务性数据并且你需要存储某些数据的审计跟踪信息,而这些数据本身是以表的形式存在的。如果你像大多数开发人员那样,那么最终所采用的方案可能如下所示:
1. 使用数据库的审计日志功能
大多数数据库都提供了插件来支持审计日志。这些插件可以很容易地安装和配置,以便于记录数据。但是,这种方式存在如下的问题:
-
完整的审计日志插件一般只有企业级版本才提供。社区版可能会缺失这样的插件。以 MySQL 为例, 审计日志插件
只有企业版中才能使用。值得一提的是,MySQL 社区版的用户依然可以安装来自 MariaDB 或 Percona 的其他审计日志组件以绕过这个限制。 -
数据库级别的审计日志会导致数据库服务器 10-20%的额外负载,正如 该文
和 该文
所讨论的。通常,对于高负载的系统,我们可能想要仅对较慢的查询启用审计日志,而不是针对所有的查询。 - 审计日志会写入到日志文件中,数据不易于搜索。为了实现数据分析和审计的目的,我们可能想要审计数据能够遵循可搜索的格式。
- 大量的审计归档文件会消耗非常重要的数据库存储,因为它们存储在与数据库相同的服务器上。
2. 使用应用程序来负责审计日志
要实现这一点,你可以采用如下的方案之一:
a.在更新现有的数据之前,复制现有的数据到另外一个表中,然后再更新当前表中的数据。
b.为数据添加一个版本号,然后每次更新都会插入一条已递增版本号的数据。
c.写入到两个数据库表中,其中一张表包含最新的数据,另外一张表包含审计跟踪信息。
作为设计可扩展系统的一项原则,我们必须要避免多次写入相同的数据,因为这不仅会降低系统的性能,还会引发各种数据不同步的问题。
那么企业为什么需要审计数据呢?
在开始介绍审计日志系统的架构之前,我们首先看一下各种组织对审计日志系统的一些需求。
- 合规性和审计:审计人员需要从他们的角度出发,以有意义和相关的方式获取数据。数据库审计日志适用于 DBA 团队,但并不适合审计人员。
- 对于任何大型软件来说,一个最基本的需求就是能够在遇到安全漏洞的时候生成重要的告警。审计日志可以用来实现这一点。
- 你必须回答各种问题,比如谁访问了数据,数据在此之前的状态是什么,在更新的时候都修改了哪些内容以及内部用户是否滥用了权限等等。
- 还有很重要的一点需要注意,因为审计跟踪信息能够有助于识别渗透者,这能够强化对“内部人员”的威慑力。人们如果知道自己的行为会被审查,那么他们就不太可能会访问未经授权的数据库或篡改特定的数据。
- 所有的行业,从金融和能源到餐饮服务和公共项目,都需要分析数据访问情况,并定期向各种政府机构提交详细的报告。根据“健康保险流通与责任法案(Health Insurance Portability and Accountability Act,HIPAA)”,该法案要求医疗服务供应商提供所有接触他们数据记录的每个人的审计跟踪数据,这个要求要到数据行和记录级别。新的欧盟通用数据保护条例(European Union General Data Protection Regulation,GDPR)也有类似的需求。萨班斯-奥克斯利法案(Sarbanes-Oxley Act,SOX)对公众公司提出了广泛的会计法规。这些组织需要定期分析数据访问情况并生成详细的报告。
在本文中,我将会使用像 Maxwell’s Daemon 和 Kafka 这样的技术提供一个可扩展的方案,以管理审计跟踪数据。
问题陈述
构建一个独立于应用程序和数据模型的审计系统。该系统必须要具备可扩展性并且经济划算。
架构
重要提示:本系统只适用于使用 MySQL 数据库的情况,并且使用基于 ROW 的 binlog日志格式
。
在我们讨论解决方案的细节之前,我们先快速看一下本文中所讨论的每项技术。
Maxwell’s Daemon
Maxwell’s Daemon
(MD)是一个来自 Zendesk
的开源项目,它会读取 MySQL bin 日志并将 ROW 更新以 JSON 的格式写入到 Kafka、Kinesis 或其他流平台上。Maxwell 的运维开销非常低,除了 MySQL 和一些写入数据的地方之外,就没有其他的需求了,如 项目网站
所述。简而言之,MD 是一个数据变化捕获(Change-Data-Capture,CDC)的工具。
市场上有很多可用的 CDC 变种,比如 Redhat 的 Debezium、Netflix 的 DBLog 以及 LinkedIn 的 Brooklyn。我们这里的环境可以采用这些工具中的任意一个来实现。但是,Netflix 的 DBLog 以及 LinkedIn 的 Brooklyn 是为了满足不足的使用场景而开发的,正如上述的链接中所阐述的那样。不过,Debezium 与 MD 非常类似,可以用来取代我们的架构中的 MD。关于该选择 MD 还是 Debezium,我简要列出了几件需要考虑的事情。
-
Debezium 只能写入数据到 Kafka 中,至少这是它支持的主要的生产者。而 MD 支持各种生产者,包括 Kafka。MD 支持的生产者是 afka, Kinesis
、 Google Cloud Pub/Sub
、 SQS
、 Rabbit MQ
和 Redis。 -
MD 提供了编写自己的生产者并对其进行配置的方案。详情可参考该 文档
。 -
Debezium 的优势在于它可以从多个源读取变化数据,比如 MySQL
、 MongoDB
、 PostgreSQL
、 SQL Server
、 Cassandra
、 DB2
和 Oracle
。在添加新的数据源方面,他们非常活跃。而 MD 目前只支持 MySQL 数据源。
Kafka
Apache Kafka
是一个开源的分布式事件流平台,能够用于高性能的数据管道、流分析、数据集成和任务关键型的应用。
MongoDB
MongoDB
是一个通用的、基于文档的分布式数据库,它是为现代应用开发人员和云时代所构建的。我们使用 MongoDB 只是为了进行阐述,你可以选择其他的方案,比如 S3
,也可以选择其他的时序数据库如 InfluxDB
或 Cassandra
。
下图展示了审计跟踪方案的数据流图。
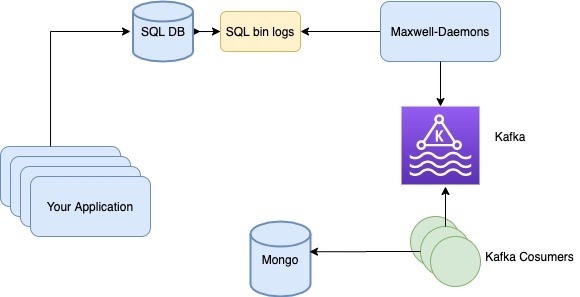
图 1 数据流图
在审计跟踪管理系统中,要涉及到如下几个步骤。
- 应用程序执行数据库写入、更新或删除操作。
- SQL 数据库将会以 ROW 格式为这些操作生成 bin 日志。这是 SQL 数据库相关的配置。
- Maxwell’s Daemon 轮询 SQL bin 日志,读取新的条目并将其写入到 Kafka 主题中。
- 消费者应用轮询 Kafka 主题以读取数据并进行处理。
- 消费者将处理后的数据写入到新的数据存储中。
环境搭建
为了实现简便的环境搭建,我们在所有可能的地方都尽可能使用 Docker 容器。如果你的机器还没有安装 docker 的话,那么可以考虑安装 Docker Desktop
。
MySQL 数据库
1.在本地运行 mysql 服务器。如下的命令将会在 3307 端口启动一个 mysql 容器。
docker run -p 3307:3306 -p 33061:33060 --name=mysql83 -d mysql/mysql-server:latest
复制代码
2.如果这是全新安装的话,我们并不知道 root 密码,运行如下的命令在控制台打印密码出来。
docker logs mysql83 2>&1 | grep GENERATED
复制代码
3.如果需要的话,登录容器并更改密码。
docker exec -it mysql83 mysql -uroot -palter user 'root'@'localhost' IDENTIFIED BY 'abcd1234'
复制代码
4.处于安全的原因,mysql docker 容器默认不允许从外部应用进行连接。我们需要运行如下的命令改变这一点。
update mysql.user set host = '%' where user='root';
复制代码
5.从 mysql 提示窗口退出并重启 docker 容器。
docker container restart mysql83
复制代码
6.重新登录 mysql 客户端并运行如下的命令为 maxwell’s daemon 创建用户。关于该步骤的详细信息,请参考 Maxwell’s Daemon的快速指南
。
docker exec -it mysql83 mysql -uroot -pset global binlog_format=ROW;set global binlog_row_image=FULL;CREATE USER 'maxwell'@'%' IDENTIFIED BY 'pmaxwell';GRANT ALL ON maxwell.* TO 'maxwell'@'%';GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';CREATE USER 'maxwell'@'localhost' IDENTIFIED BY 'pmaxwell';GRANT ALL ON maxwell.* TO 'maxwell'@'localhost';GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'localhost';
复制代码
Kafka 代理
搭建 Kafka 是一项非常简单直接的任务。从 该链接
下载 Kafka。
运行如下的命令:
提取 Kafka
tar -xzf kafka_2.13-2.6.0.tgzcd kafka_2.13-2.6.0
复制代码
运行 Zookeeper,这是目前使用 Kafka 所需要的
bin/zookeeper-server-start.sh config/zookeeper.properties
复制代码
在一个单独的终端启动 Kafka
bin/kafka-server-start.sh config/server.properties
复制代码
在一个单独的终端创建主题
bin/kafka-topics.sh --create --topic maxwell-events --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
复制代码
上述的命令会启动一个 Kafka 代理并在其中创建一个名为“ maxwell-events
”的主题。
要推送消息到该 Kafka 主题,我们可以在新的终端运行如下的命令
bin/kafka-console-producer.sh --topic maxwell-events --broker-list localhost:9092
复制代码
上述的命令会给我们显示一个提示,从中可以输入消息内容,然后点击回车键,以便于发送消息到 Kafka 中。
消费来自 Kafka 主题的消息
bin/kafka-console-producer.sh --topic quickstart-events --broker-list localhost:9092
复制代码
Maxwell’s Daemon
通过该 地址
下载 maxwell’s daemon。
将其解压并运行如下的命令。
bin/maxwell --user=maxwell --password=pmaxwell --host=localhost --port=3307 --producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=maxwell-events
复制代码
这样的话,我们就建立好了 Maxwell 来监控前面所搭建的数据库的 bin 日志。当然,我们也可以只监控几个数据库或几个表。关于这方面的更多信息,请参考 Maxwell’s Daemon配置
文档。
测试环境
要测试搭建的环境是否正确的话,我们可以连接 MySQL,并在一张表中插入一些数据。
docker exec -it mysql83 mysql -uroot -pCREATE DATABASE maxwelltest;USE maxwelltest;CREATE TABLE Persons (PersonId int NOT NULL AUTO_INCREMENT,LastName varchar(255),FirstName varchar(255),City varchar(255),primary key (PersonId));INSERT INTO Persons (LastName, FirstName, City) VALUES ('Erichsen', 'Tom', 'Stavanger');
复制代码
现在,在另外一个终端中,运行如下的命令:
bin/kafka-console-consumer.sh --topic maxwell-events --from-beginning --bootstrap-server localhost:9092
复制代码
在终端中,你应该能够看到如下所示的内容:
{"database":"maxwelltest","table":"Persons","type":"insert","ts":1602904030,"xid":17358,"commit":true,"data":{"PersonId":1,"LastName":"Erichsen","FirstName":"Tom","City":"Stavanger"}}
复制代码
正如我们所看到的,Maxwell’s Daemon 捕获到了数据库插入事件并写入一个 JSON 字符串到 Kafka 主题中,其中包含了事件的详情。
搭建 MongoDB
要在本地运行 MongoDB,可以运行如下的命令:
docker run --name mongolocal -p 27017:27017 mongo:latest
复制代码
Kafka 消费者
Kafka-consumer 的代码可以通过 GitHub项目
获取。下载源码并参考 README 文档以了解如何运行。
最终测试
最后,我们的环境搭建终于完成了。登录 MySQL 数据库并运行任意的插入、删除或更新命令。如果环境搭建正确的话,将会在 mongodb auditlog 数据库中看到相应的条目。我们可以愉快地开始进行审计了!
结论
在本文中所描述的系统在实际部署中能够很好地运行,为我们提供了一个用户数据之外的额外数据源,但是在采用这种架构之前,有些权衡你必须要注意。
- 基础设施成本:要运行这种环境,需要额外的基础设施。数据要经历网络上的多次跳转,从数据库到 Kafka,再到另外一个数据库,后面可能还会到一个备份中。这会增加基础设施的成本。
- 因为数据要经历多次跳转,审计日志无法以实时的形式进行维护。它可能会延迟几秒到几分钟。我们可能会反问“谁能需要实时的审计日志呢?”但是,如果你计划使用这种数据进行实时监控的话,必须要考虑到这一点。
- 在这个架构中,我们捕获了数据的变化,而不是谁改变了数据。如果你还关心哪个数据库用户改变了数据的话,那么这种设计就不能提供直接的支持了。
在强调完这种架构的一些权衡之后,我想重申一下这种环境的收益,它的主要好处在于:
- 这种环境减少了数据库在审计日志方面的性能损耗,并且满足传统数据源在市场营销和告警方面的需要。
- 易于搭建,并且比较健壮:环境中任意组件的任意问题都不会造成数据的丢失。例如,如果 MD 出现故障的话,数据依然会保存在 bin 日志文件中,当 daemon 下次运行的时候,能够从上次处理的地方继续读取。如果 Kafka 代理出现故障的话,MD 能够探测到并且会停止从 bin 日志中读取数据。如果 Kafka 消费者崩溃的话,数据会依然保留在 Kafka 代理中。所以,在最糟糕的情况下,审计日志会延迟但是不会出现数据丢失。
- 环境搭建过程非常简单,并不需要耗费太多的开发精力。
作者简介
Vishal Sinha 是一位充满激情的技术专家,对分布式计算和大型可扩展系统有着专业的知识和浓厚的兴趣。目前,他在一家领先的印度独角兽公司担任技术总监。在 16 年的软件行业生涯中,他曾在多家跨国公司和创业公司工作,开发过各种大规模的系统,并领导过一个由众多软件工程师组成的团队。他喜欢解决复杂的问题和尝试新技术。
原文链接:
Building a SQL Database Audit System using Kafka, MongoDB and Maxwell’s Daemon