微信小程序实战——高仿知乎日报(中)
要做微信小程序首先要对html,css,js有一定的基础,还有对微信小程序的API也要非常熟悉
我将该教程分为以下三篇
微信小程序实战——高仿知乎日报(上)
微信小程序实战——高仿知乎日报(中)
微信小程序实战——高仿知乎日报(下)
三篇分别讲不同的组件和功能块
这篇这要讲
- 日报详情页
- 底部工具栏
- 评论页面
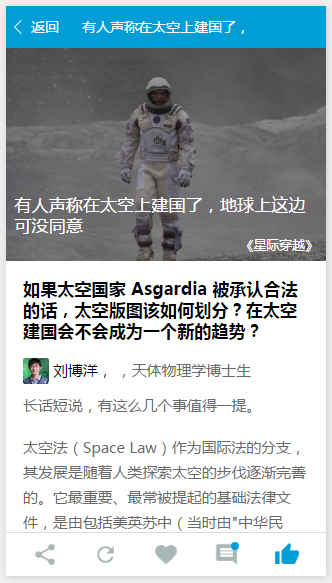
日报详情页
日报的内容也是最难做的,因为接口返回的内容是html…,天呀,是html!小程序肯本就不支持,解析html的过程非常痛苦,因为本人的正则表达式只是几乎为0,解析方案的寻找过程很虐心,经典的jQuery是用不了了,又没有dom,无法用传统的方式解析html。尝试了正则学习,但是也是无法在短时间内掌握,寻找了很多解析库,大多是依赖浏览器api。不过,上天是不会忽视有心人的,哈哈,还是被我找到了解决方案。幸运的我发现了一个用正则编写的和类似与语法分析方法的xml解析库。这个库是一个very good的网友封装的html解析库。详情点击 用Javascript解析html。
由于日报详情内容的html部分结构太大,这里只列出了简要的结构,这个结构是通用的(不过不保证知乎会变动结构,要是变动了,之前的解析可能就没用了…心累)
<div class="question">
<h2 class="question-title">日本的六大财阀现在怎么样了?</h2>
<div class="answer">
<div class="meta">
<img class="avatar" src="http://pic1.zhimg.com/e53a7f35d5b1e27b00aa90a2c1468a8c_is.jpg">
<span class="author">leon,</span><span class="bio">data analyst</span>
</div>
<div class="content">
<p>“财阀”在战后统称为 Group(集团),是以银行和传统工业企业为核心的松散集合体,由于历史渊源而有相互持股。</p>
<p>Group 对于当今日本企业的意义在于:</p>
<p><strong>MUFG:三菱集团、三和集团(みどり会)</strong></p>
<p><img class="content-image" src="http://pic1.zhimg.com/70/90c319ac7a7b2723e5b511de954f45bc_b.jpg" alt=""
/></p>
</div>
</div>
<div class="view-more"><a href="http://www.zhihu.com/question/23907827">查看知乎讨论<span class="js-question-holder"></span></a></div>
</div>外层的.question是日报中问题答案的显示单位,可能有多个,因此需要循环显示。.question-title是问题的标题,.meta中是作者的信息,img.avatar是用户的头像,span.author是用户的名称,span.bio可能使用户的签名吧。最难解析的是.content中的内容,比较多。但是有个规律就是都是以<p>标签包裹着,获取了.content中的所有p就可以得到所有的段落。之后再解析出段落中的图片。
以下是详情页的内容展示模版
<view style="padding-bottom: 150rpx;">
<block wx:for="{{news.body}}">
<view class="article">
<view class="title" wx:if="{{item.title && item.title != ''}}">
<text>{{item.title}}</text>
</view>
<view class="author-info" wx:if="{{(item.avatar && item.avatar != '') || (item.author && item.author != '') || (item.bio && item.bio != '')}}">
<image wx:if="{{item.avatar && item.avatar != ''}}" class="avatar" src="{{item.avatar}}"></image>
<text wx:if="{{item.author && item.author != ''}}" class="author-name">{{item.author}}</text>
<text wx:if="{{item.bio && item.bio != ''}}" class="author-mark">,{{item.bio}}</text>
</view>
<view class="content" wx:if="{{item.content && item.content.length > 0}}">
<block wx:for="{{item.content}}" wx:for-item="it">
<block wx:if="{{it.type == 'p'}}">
<text>{{it.value}}</text>
</block>
<block wx:elif="{{it.type == 'img'}}">
<image mode="aspectFill" src="{{it.value}}" data-src="{{it.value}}" bindtap="previewImgEvent" />
</block>
<block wx:elif="{{it.type == 'pstrong'}}">
<text class="strong">{{it.value}}</text>
</block>
<block wx:elif="{{it.type == 'pem'}}">
<text class="em">{{it.value}}</text>
</block>
<block wx:elif="{{it.type == 'blockquote'}}">
<text class="qoute">{{it.value}}</text>
</block>
<block wx:else>
<text>{{it.value}}</text>
</block>
</block>
</view>
<view class="discuss" wx:if="{{item.more && item.more != ''}}">
<navigator url="{{item.more}}">查看知乎讨论</navigator>
</view>
</view>
</block>
</view>可以看出模版中的内容展示部分用了蛮多的block加判断语句wx:if wx:elif wx:else。这些都是为了需要根据解析后的内容类型来判断需要展示什么标签和样式。解析后的内容大概格式是这样的:
{
body: [
title: '标题',
author: '作者',
bio: '签名',
avatar: '头像',
more: '更多地址',
content: [ //内容
{
type: 'p',
value: '普通段落内容'
},
{
type: 'img',
value: 'http://xxx.xx.xx/1.jpg'
},
{
type: 'pem',
value: '...'
},
...
]
],
...
}需要注意的一点是主题日报有时候返回的html内容是经过unicode编码的不能直接显示,里边全是类似&#xxxx;的字符,这需要单独为主题日报的日报详情解析编码,微信小程序是不会解析特殊符号的,我们要手动转换,这里只转了最常用几个。
再点击主题日报中的列表项是,传递一个标记是主题日报的参数theme
//跳转到日报详情页
toDetailPage: function( e ) {
var id = e.currentTarget.dataset.id;
wx.navigateTo( {
url: '../detail/detail?theme=1&id=' + id
});
}, 然后在Detail.js的onLoad事件中接受参数
//获取列表残过来的参数 id:日报id, theme:是否是主题日报内容(因为主题日报的内容有些需要单独解析)
onLoad: function( options ) {
var id = options.id;
var isTheme = options[ 'theme' ];
this.setData( { id: id, isTheme: isTheme });
},之后开始请求接口获取日报详情,并根据是否是主题日报进行个性化解析
//加载页面相关数据
function loadData() {
var _this = this;
var id = this.data.id;
var isTheme = this.data.isTheme;
//获取日报详情内容
_this.setData( { loading: true });
requests.getNewsDetail( id, ( data ) => {
data.body = utils.parseStory( data.body, isTheme );
_this.setData( { news: data, pageShow: 'block' });
wx.setNavigationBarTitle( { title: data.title }); //设置标题
}, null, () => {
_this.setData( { loading: false });
});
}以上传入一个isTheme参数进入解析方法,解析方法根据此参数判断是否需要进行单独的编码解析。
内容解析的库代码比较多,就不贴出了,可以到git上查看。这里给出解析的封装。
var HtmlParser = require( 'htmlParseUtil.js' );
String.prototype.trim = function() {
return this.replace( /(^s*)|(s*$)/g, '' );
}
String.prototype.isEmpty = function() {
return this.trim() == '';
}
/**
* 快捷方法 获取HtmlParser对象
* @param {string} html html文本
* @return {object} HtmlParser
*/
function $( html ) {
return new HtmlParser( html );
}
/**
* 解析story对象的body部分
* @param {string} html body的html文本
* @param {boolean} isDecode 是否需要unicode解析
* @return {object} 解析后的对象
*/
function parseStory( html, isDecode ) {
var questionArr = $( html ).tag( 'div' ).attr( 'class', 'question' ).match();
var stories = [];
var $story;
if( questionArr ) {
for( var i = 0, len = questionArr.length;i < len;i++ ) {
$story = $( questionArr[ i ] );
stories.push( {
title: getArrayContent( $story.tag( 'h2' ).attr( 'class', 'question-title' ).match() ),
avatar: getArrayContent( getArrayContent( $story.tag( 'div' ).attr( 'class', 'meta' ).match() ).jhe_ma( 'img', 'src' ) ),
author: getArrayContent( $story.tag( 'span' ).attr( 'class', 'author' ).match() ),
bio: getArrayContent( $story.tag( 'span' ).attr( 'class', 'bio' ).match() ),
content: parseStoryContent( $story, isDecode ),
more: getArrayContent( getArrayContent( $( html ).tag( 'div' ).attr( 'class', 'view-more' ).match() ).jhe_ma( 'a', 'href' ) )
});
}
}
return stories;
}
/**
* 解析文章内容
* @param {string} $story htmlparser对象
* @param {boolean} isDecode 是否需要unicode解析
* @returb {object} 文章内容对象
*/
function parseStoryContent( $story, isDecode ) {
var content = [];
var ps = $story.tag( 'p' ).match();
var p, strong, img, blockquote, em;
if( ps ) {
for( var i = 0, len = ps.length;i < len;i++ ) {
p = transferSign(ps[ i ]); //获取<p>的内容 ,并将特殊符号转义
if( !p || p.isEmpty() )
continue;
img = getArrayContent(( p.jhe_ma( 'img', 'src' ) ) );
strong = getArrayContent( p.jhe_om( 'strong' ) );
em = getArrayContent( p.jhe_om( 'em' ) );
blockquote = getArrayContent( p.jhe_om( 'blockquote' ) );
if( !img.isEmpty() ) { //获取图片
img=img.replace("pic1","pic3");
img=img.replace("pic2","pic3");
content.push( { type: 'img', value: img });
}
else if( isOnly( p, strong ) ) { //获取加粗段落<p><strong>...</strong></p>
strong = decodeHtml( strong, isDecode );
if( !strong.isEmpty() )
content.push( { type: 'pstrong', value: strong });
}
else if( isOnly( p, em ) ) { //获取强调段落 <p><em>...</em></p>
em = decodeHtml( em, isDecode );
if( !em.isEmpty() )
content.push( { type: 'pem', value: em });
}
else if( isOnly( p, blockquote ) ) { //获取引用块 <p><blockquote>...</blockquote></p>
blockquote = decodeHtml( blockquote, isDecode );
if( !blockquote.isEmpty() )
content.push( { type: 'blockquote', value: blockquote });
}
else { //其他类型 归类为普通段落 ....太累了 不想解析了T_T
p = decodeHtml( p, isDecode );
if( !p.isEmpty() )
content.push( { type: 'p', value: p });
}
}
}
return content;
}
/**
* 取出多余或者难以解析的html并且替换转义符号
*/
function decodeHtml( value, isDecode ) {
if( !value ) return '';
value = value.replace( /<[^>]+>/g, '' )
.replace( / /g, ' ' )
.replace( /“/g, '"' )
.replace( /”/g, '"' ).replace( /·/g, '·' );
if( isDecode )
return decodeUnicode( value.replace( /&#/g, 'u' ) );
return value;
}
/**
* 解析段落的unicode字符,主题日报中的内容又很多是编码过的
*/
function decodeUnicode( str ) {
var ret = '';
var splits = str.split( ';' );
for( let i = 0;i < splits.length;i++ ) {
ret += spliteDecode( splits[ i ] );
}
return ret;
};
/**
* 解析单个unidecode字符
*/
function spliteDecode( value ) {
var target = value.match( /ud+/g );
if( target && target.length > 0 ) { //解析类似 "7.1 u20998" 参杂其他字符
target = target[ 0 ];
var temp = value.replace( target, '{{@}}' );
target = target.replace( 'u', '' );
target = String.fromCharCode( parseInt( target ) );
return temp.replace( "{{@}}", target );
} else {
// value = value.replace( 'u', '' );
// return String.fromCharCode( parseInt( value, '10' ) )
return value;
}
}
/**
* 获取数组中的内容(一般为第一个元素)
* @param {array} arr 内容数组
* @return {string} 内容
*/
function getArrayContent( arr ) {
if( !arr || arr.length == 0 ) return '';
return arr[ 0 ];
}
function isOnly( src, target ) {
return src.trim() == target;
}
module.exports = {
parseStory: parseStory
}
/**
* 将转义字符转为实体
* @param data
* @returns {*}
*/
function transferSign(data){
data=data.replace(/–/g,"–");
data=data.replace(/—/g,"—");
data=data.replace(/…/g,"…");
data=data.replace(/•/g,"•");
data=data.replace(/’/g,"’");
data=data.replace(/–/g,"–");
return data;
}
代码的解析过程比较繁杂,大家可以根据返回的html结构和参照解析库的作者写的文章来解读。
底部工具栏
一般资讯APP的详情页都有一个底部的工具栏用于操作分享、收藏、评论和点赞等等。为了更好地锻炼动手能力,自己也做了一个底部工具栏,虽然官方的APP并没有这个东西。前面介绍到的获取额外信息API在这里就被使用了。本来自己是想把推荐人数和评论数显示在底部的图片右上角,但是由于本人的设计问题,底部的字号已经是很小了,显示数量的地方的字号又不能再小了,这样看起来数字显示的地方和图标的大小几乎一样,很是别扭,所以就不现实数字了。
<view class="toolbar">
<view class="inner">
<view class="item" bindtap="showModalEvent"><image src="../../images/share.png" /></view>
<view class="item" bindtap="reloadEvent"><image src="../../images/refresh.png" /></view>
<view class="item" bindtap="collectOrNot" wx:if="{{isCollect}}"><image src="../../images/star_yellow.png" /></view>
<view class="item" bindtap="collectOrNot" wx:else><image src="../../images/star.png" /></view>
<view class="item" data-id="{{id}}" bindtap="toCommentPage"><image src="../../images/insert_comment.png" />
<view class="tip"></view>
</view>
<view class="item">
<image src="../../images/thumb_up.png" />
</view>
</view>
</view>底部有分享、收藏、评论和点赞按钮,收藏功能主要用到数据的储存,存在就去掉后储存,不存在就添加后储存
collectOrNot: function() {
var pageData = wx.getStorageSync('pageData') || []
console.log(pageData);
if (this.data.isCollect){
for(var i=0;i<pageData.length;i++){
if (pageData[i].id==this.data.id){
pageData.splice(i,1);
this.setData( { isCollect: false });
break;
}
}
}else {
var images=new Array(this.data.news.image);
var item ={id:this.data.id,title:this.data.news.title,images:images};
console.log(item);
pageData.unshift(item);
this.setData( { isCollect: true });
}
try {
wx.setStorageSync('pageData',pageData);
} catch (e) {
}
console.log(pageData);
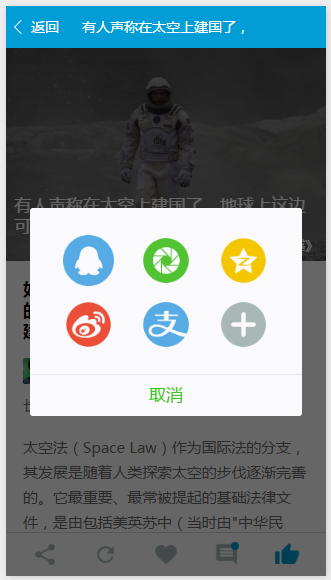
}分享肯定是做不了啦,哈哈,但是效果还是需要有的,就一个modal弹窗,显示各类社交应用的图标就行啦。
<modal class="modal" confirm-text="取消" no-cancel hidden="{{modalHidden}}" bindconfirm="hideModalEvent">
<view class="share-list">
<view class="item"><image src="../../images/share_qq.png" /></view>
<view class="item"><image src="../../images/share_pengyouquan.png" /></view>
<view class="item"><image src="../../images/share_qzone.png" /></view>
</view>
<view class="share-list" style="margin-top: 20rpx">
<view class="item"><image src="../../images/share_weibo.png" /></view>
<view class="item"><image src="../../images/share_alipay.png" /></view>
<view class="item"><image src="../../images/share_plus.png" /></view>
</view>
</modal>model的隐藏和显示都是通过hidden属性来控制。
底部工具栏中还有一个按钮是刷新,其实就是一个重新调用接口请求数据的过程而已。
//重新加载数据
reloadEvent: function() {
loadData.call( this );
},
评论页面
评论页面蛮简单的,就是展示评论列表,但是要展示两部分,一部分是长评,另一部分是短评。长评跟短评的布局都是通用的。进入到评论页面时,如果长评有数据,则先加载长评,短评需要用户点击短评标题才加载,否则就直接加载短评。这需要上一个详情页面中传递日报的额外信息过来(即长评数量和短评数量)。
之前已经在日报详情页面中,顺便加载了额外的信息
//请求日报额外信息(主要是评论数和推荐人数)
requests.getStoryExtraInfo( id, ( data ) => {
_this.setData( { extraInfo: data });
});在跳转到评论页面的时候顺便传递评论数量,这样我们就不用在评论页面在请求一次额外信息了。
//跳转到评论页面
toCommentPage: function( e ) {
var storyId = e.currentTarget.dataset.id;
var longCommentCount = this.data.extraInfo ? this.data.extraInfo.long_comments : 0; //长评数目
var shortCommentCount = this.data.extraInfo ? this.data.extraInfo.short_comments : 0; //短评数目
//跳转到评论页面,并传递评论数目信息
wx.navigateTo( {
url: '../comment/comment?lcount=' + longCommentCount + '&scount=' + shortCommentCount + '&id=' + storyId
});
}评论页面接受参数
//获取传递过来的日报id 和 评论数目
onLoad: function( options ) {
var storyId = options[ 'id' ];
var longCommentCount = parseInt( options[ 'lcount' ] );
var shortCommentCount = parseInt( options[ 'scount' ] );
this.setData( { storyId: storyId, longCommentCount: longCommentCount, shortCommentCount: shortCommentCount });
},进入页面立刻加载数据
//加载长评列表
onReady: function() {
var storyId = this.data.storyId;
var _this = this;
this.setData( { loading: true, toastHidden: true });
//如果长评数量大于0,则加载长评,否则加载短评
if( this.data.longCommentCount > 0 ) {
requests.getStoryLongComments( storyId, ( data ) => {
console.log( data );
_this.setData( { longCommentData: data.comments });
}, () => {
_this.setData( { toastHidden: false, toastMsg: '请求失败' });
}, () => {
_this.setData( { loading: false });
});
} else {
loadShortComments.call( this );
}
}
/**
* 加载短评列表
*/
function loadShortComments() {
var storyId = this.data.storyId;
var _this = this;
this.setData( { loading: true, toastHidden: true });
requests.getStoryShortComments( storyId, ( data ) => {
_this.setData( { shortCommentData: data.comments });
}, () => {
_this.setData( { toastHidden: false, toastMsg: '请求失败' });
}, () => {
_this.setData( { loading: false });
});
}评论页面的展示也是非常的简单,一下给出长评模版,短评也是一样的,里面的点赞按钮功能木有实现哦。
<view class="headline">
<text>{{longCommentCount}}条长评</text>
</view>
<view class="common-list">
<block wx:for="{{longCommentData}}">
<view class="list-item has-img" data-id="{{item.id}}">
<view class="content">
<view class="header">
<text class="title">{{item.author}}</text>
<image class="vote" src="../../images/thumb_up.png" />
</view>
<text class="body">{{item.content}}</text>
<text class="bottom">{{item.time}}</text>
</view>
<image src="{{item.avatar}}" class="cover" />
</view>
</block>
</view>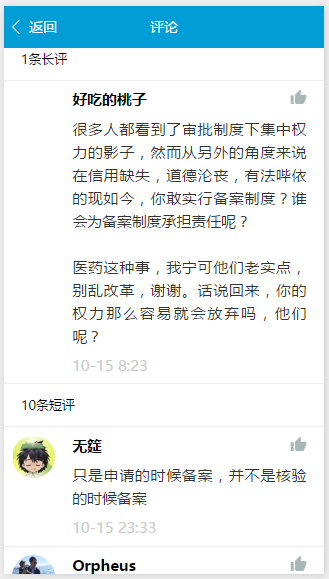
About The Author
bjmayor
程序员,码农,php,python,ios,android,go,产品经理,创业。