Linux中查看文本文件命令分享-演道网
tail命令查看日志信息
实时监控日志:
linuxidc@linuxidc:~/www.linuxidc.com$ tail -f linuxidc.com.txt
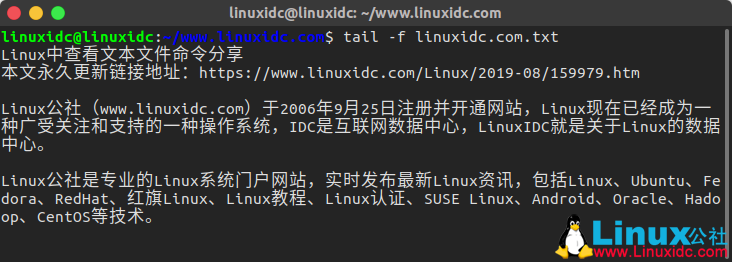
实时监控2行日志信息:
linuxidc@linuxidc:~/www.linuxidc.com$ tail -2f linuxidc.com.txt
查看日志尾部的最后100行日志信息:
linuxidc@linuxidc:~/www.linuxidc.com$ tail -n 100 linuxidc.com.txt
查看日志100行之后的日志信息:
linuxidc@linuxidc:~/www.linuxidc.com$ tail -n +100 linuxidc.com.txt
head命令查看文本信息
查看文本开始的头100行信息:
linuxidc@linuxidc:~/www.linuxidc.com$ head -n 100 linuxidc.com.txt
查看文本最后100行信息以上的内容
linuxidc@linuxidc:~/www.linuxidc.com$ head -n -100 linuxidc.com.txt
cat命令查看文本信息
查看全部文本内容
linuxidc@linuxidc:~/www.linuxidc.com$ cat linuxidc.com.txt
查看文本的中间某些行范围之间的内容,例如说查看文本文件100-120行之间的内容:
linuxidc@linuxidc:~/www.linuxidc.com$ cat -n linuxidc.com.txt |tail -n +100|head -n 20
不过使用个人不是太喜欢使用这种命令来进行文本的定位查看,因为查看起来过于麻烦,文章下边会有更加简便的命令操作。
tac查看文本信息
和cat命令有点相反,cat命令更多的是从头部往尾部的顺序展现文本内容,而tac命令正好是从文本的尾部往头部展现日志内容
linuxidc@linuxidc:~/www.linuxidc.com$ tac linuxidc.com.txt
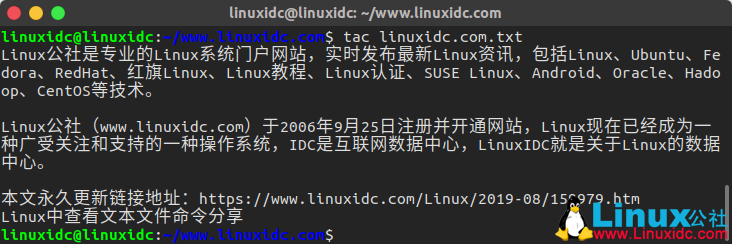
例如说,我们通过cat命令和tac命令同时来查看一段相同的内容:
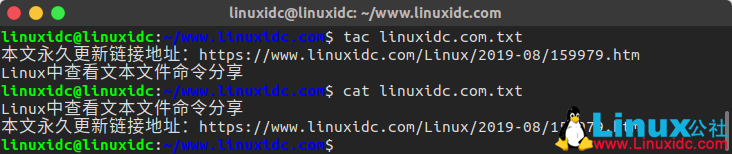
通过不同命令来展示文本,会发现文本的内容顺序有所相反。
搜索文本内容
grep是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep命令的常用方式:
在多个文件中查找:
grep “match_pattern” file_1 file_2 file_3 …
标记匹配颜色 –color=auto 选项:
grep “match_pattern” file_name –color=auto
//【这里的color项可以根据文档说明进行选择always,never,auto三种】
输出除之外的所有行 -v 选项:
grep -v “match_pattern” file_name
使用正则表达式 -E 选项:
grep -E “[1-9]+”
只输出匹配到的内容选项:
grep -o -E “[a-z]+.” line
统计文件或者文本中包含匹配字符串的行数 -c 选项:
grep -c “text” file_name
输出包含匹配字符串的行数 -n 选项:
grep “text” -n file_name
在了解了grep命令能完成的功能点之后,我们可以在实际工作中灵活运用。
有些时候我们也会遇到一些希望查看某个时间段日志信息的需要,这个时候可以利用grep这条命令来实现这个功能,例如说希望查看2019-08-06 19点这一个小时以内的日志信息,那么可以输入以下命令:
grep ‘2019-08-12 19’ log.file
这样可以快速定位到你所希望查看的信息范围。
由于grep命令是可以接收standard input的数据,因此我们通常可以借助管道命令符“ | ”的帮助,在一些标准输出进行中进行查找操作。
例如说,先将文件的内容读取出来,然后借助管道的帮助将内容转发给grep来进行内容过滤,如下边的这段命令:
cat log.file |grep -n ‘2019-08-12 22:00’
除了使用grep命令之外,也可以使用sed命令来实现相应的效果。
sed是一种非交互式的编辑器,sed会逐行处理文件(或输入),并将结果发送到屏幕。
可能对于新手来说,讲概念还不如直接来几个实操案例更为直接。
sed命令的常用方式:
只打印文件的第一行内容
sed -n ‘1p’ filename
查看文件的第一行到第十行之间的内容
sed -n ‘1,10p’ filename
删除第一行文本信息
sed ‘1d’ filename
将文本里面的某些字符串进行替换
sed ‘s/希望替换的内容/被替换的内容/g’
例如:sed ‘s/1/one /g’ filename 将1替换为one
在了解了sed命令的一些基础用法之后,我们可以在实际的工作场景中多次运用,从而强化自己对于sed命令的理解。
例如说,通过sed命令来进行日期范围的指定,例如说查看2019-08-06 22:43-22:44之间的日志记录:
sed -n ‘/2019-08-12 22:00/,/2019-08-12 22:01/p’ filename
上边有说到使用head和tail命令一起来实现对于日志文件的某段内容查看,但是这样的操作实在是有点麻烦,不妨可以尝试使用sed命令来进行操作。
例如说,查看日志的第1-20行内容:
nl log.file | sed -n ‘1,10p’
利用more命令进行翻页查看
如果说希望查看的日志文件过大,那么可以通过使用more命令来进行分页查找,例如说设定每一页展示10条数据信息:
more -10 filename
通过使用more命令可以查看到每一页展示的数据,同时通过敲空格键会进行下一页的跳转。同时在窗口中也会显示当前所阅读的文本内容的基础进度。
说了那么多,我们不妨进行一些模拟的操作场景吧:
查看日志最后一次出现关键字’test’的日志记录
grep ‘test’ -A 10 log.file | tail -n 11
这里需要了解到grep命令的几个参数含义:
- grep ‘name’ -A 10 显示匹配内容和后面的10行
- grep ‘name’ -B 10 显示匹配内容和前面的10行
- grep ‘name’ -C 10 显示匹配内容和前后面的10行
tail -n 11命令则是将当前显示的10行内容以及匹配的那一行内容展示出现
简单统计一份日志里面出现‘test’关键字的行数
相应命令:
grep ‘test’ ./log.file |wc -l
这里我们可以先将文本的内容进行输出到标准输出中,然后借助管道将数据信息传给wc命令进行统计。
wc命令常用的几个参数
-l 匹配的行数
-w 匹配的字数
-m 匹配的字符数目
Linux里面对于文本信息的查看技巧实在是有太多了,远远不局限于我在文中所提及的这些,因此在实际的工作中我们还可以多多将有助于自己提升工作效率的技巧进行归纳和总结。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.as
转载自演道,想查看更及时的互联网产品技术热点文章请点击http://go2live.cn
About The Author
maynard
懒散,不想无聊