Go语言高级编程-学习摘要
[TOC]
《Go语言高级编程》作者: 柴树衫, 曹春晖。 在线地址: https://books.studygolang.com/advanced-go-programming-book/
cgo
简单示例
package main
/*
#include <stdio.h>
static void SayHello( const char* s) {
puts(s);
}
*/
import "C"
func main() {
C.SayHello(C.CString("Hello, World!\n"))
}
说明:
import "C"表示这个是一个cgo程序,go build命令会在编译和链接阶段启动gcc编译器。- import 前的注释是有用的,表示的
C代码。这里是内链,你也可以include其他C头文件C.Sayhello和C.CString都是调用C函数- 这其实也是一个简单的
go调用C的示例代码。
模块分离
可以把SayHello的定义分离到hello.h文件,实现只要遵循规则即可,可以是C实现,可以是C++实现, 也可以是go实现。
C实现
// hello.c
#include "hello.h"
#include <stdio.h>
void SayHello(const char* s) {
puts(s);
}
c++实现
“`c++
#include <iostream>
extern "C" {
#include "hello.h"
}
void SayHello(const char* s) {
std::cout << s;
}
<pre><code class="">### go实现
“`go
// hello.go
package main
import “C”
import “fmt”
//export SayHello
func SayHello(s *C.char) {
fmt.Print(C.GoString(s))
}
说明:
1.通过CGO的
//export SayHello指令将Go语言实现的函数SayHello导出为C语言函数。
- 这里其实有两个版本的SayHello函数:一个Go语言环境的;另一个是C语言环境的。cgo生成的C语言版本SayHello函数最终会通过桥接代码调用Go语言版本的SayHello函数。
流程示例
package main
//void SayHello(_GoString_ s);
import "C"
import (
"fmt"
)
func main() {
C.SayHello("Hello, World\n")
}
//export SayHello
func SayHello(s string) {
fmt.Print(s)
}
main是入口- 然后调用
CGO自动生成的SayHello桥接函数- 调用
Go语言环境的Sayhello函数。
之所以SayHello可以直接用Go的string类型,是因为CGO增加了一个_GoString_预定义的C语言函数,用来表示Go语言字符串。
CGO基础
交叉编译时,CGO默认是禁止的,打开是设置环境变量CGO_ENABLED=1
import “C”语句
cgo将当前包引用的C语言符号都放到了虚拟的C包中,同时当前包依赖的其它Go语言包内部可能也通过cgo引入了相似的虚拟C包,但是不同的Go语言包引入的虚拟的C包之间的类型是不能通用的。
定义
package cgo_helper
//#include <stdio.h>
import "C"
type CChar C.char
func (p *CChar) GoString() string {
return C.GoString((*C.char)(p))
}
func PrintCString(cs *C.char) {
C.puts(cs)
}
使用
package main
//static const char* cs = "hello";
import "C"
import "./cgo_helper"
func main() {
cgo_helper.PrintCString(C.cs)
}
这个代码无法编译通过。
因为,使用的时候C.cs的类型其实是*main.C.char
而定义的PrintCString接受的参数类型是*cgo_helper.C.char
cgo语句
在import "C"语句前的注释中可以通过#cgo语句设置编译阶段和链接阶段的相关参数。
// #cgo CFLAGS: -DPNG_DEBUG=1 -I./include
// #cgo LDFLAGS: -L/usr/local/lib -lpng
// #include <png.h>
import "C"
编译阶段的参数主要用于定义相关宏和指定头文件检索路径。CFLAGS部分,-D部分定义了宏PNG_DEBUG,值为1;-I定义了头文件包含的检索目录。
链接阶段的参数主要是指定库文件检索路径和要链接的库文件。LDFLAGS部分,-L指定了链接时库文件检索目录,-l指定了链接时需要链接png库。
#cgo语句主要影响CFLAGS、CPPFLAGS、CXXFLAGS、FFLAGS和LDFLAGS几个编译器环境变量。
#cgo指令还支持条件选择,当满足某个操作系统或某个CPU架构类型时后面的编译或链接选项生效。比如下面是分别针对windows和非windows下平台的编译和链接选项:
// #cgo windows CFLAGS: -DX86=1
// #cgo !windows LDFLAGS: -lm
build tag 条件编译
build tag 是在Go或cgo环境下的C/C++文件开头的一种特殊的注释。
比如下面的源文件只有在设置debug构建标志时才会被构建:
// +build debug
package main
var buildMode = "debug"
利用tags可以为go的二进制生成版本信息。参考https://www.cnblogs.com/linyihai/p/10859945.html
类型转换
数值类型
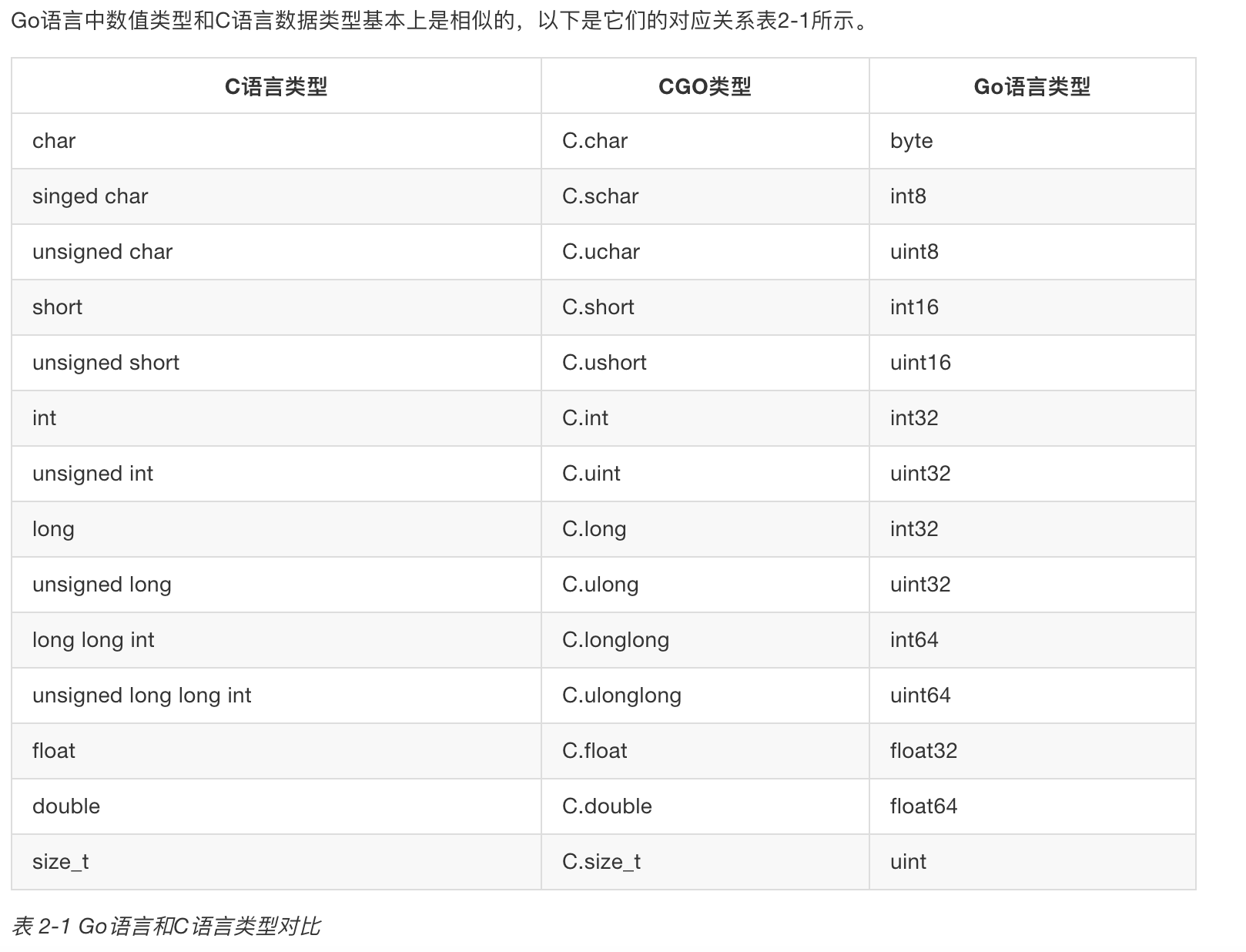
GO只能通过虚拟的C包访问C的类型,也即表中的CGO类型
如果需要在C语言中访问Go语言的int类型,可以通过GoInt类型访问,GoInt类型在CGO工具生成的_cgo_export.h头文件中定义。其实在_cgo_export.h头文件中,每个基本的Go数值类型都定义了对应的C语言类型,它们一般都是以单词Go为前缀。下面是64位环境下,_cgo_export.h头文件生成的Go数值类型的定义,其中GoInt和GoUint类型分别对应GoInt64和GoUint64:
typedef signed char GoInt8;
typedef unsigned char GoUint8;
typedef short GoInt16;
typedef unsigned short GoUint16;
typedef int GoInt32;
typedef unsigned int GoUint32;
typedef long long GoInt64;
typedef unsigned long long GoUint64;
typedef GoInt64 GoInt;
typedef GoUint64 GoUint;
typedef float GoFloat32;
typedef double GoFloat64;
C通过_cgo_export.h头文件定义的类型访问Go数据类型。
除了GoInt和GoUint之外,我们并不推荐直接访问GoInt32、GoInt64等类型。更好的做法是通过C语言的C99标准引入的<stdint.h>头文件。为了提高C语言的可移植性,在<stdint.h>文件中,不但每个数值类型都提供了明确内存大小,而且和Go语言的类型命名更加一致。
Go 字符串和切片
在CGO生成的_cgo_export.h头文件中还会为Go语言的字符串、切片、字典、接口和管道等特有的数据类型生成对应的C语言类型:
typedef struct { const char *p; GoInt n; } GoString;
typedef void *GoMap;
typedef void *GoChan;
typedef struct { void *t; void *v; } GoInterface;
typedef struct { void *data; GoInt len; GoInt cap; } GoSlice;
不过需要注意的是,其中只有字符串和切片在CGO中有一定的使用价值,因为CGO为他们的某些GO语言版本的操作函数生成了C语言版本,因此二者可以在Go调用C语言函数时马上使用;
结构体、联合、枚举类型
结构体的简单用法如下:
/*
struct A {
int i;
float f;
int type; // type 是 Go 语言的关键字
float _type; // 将屏蔽CGO对 type 成员的访问
};
*/
import "C"
import "fmt"
func main() {
var a C.struct_A
fmt.Println(a.i)
fmt.Println(a.f)
fmt.Println(a._type)
}
说明:
- 如果结构体的成员名字中碰巧是Go语言的关键字,可以通过在成员名开头添加下划线来访问:
- 但是如果有2个成员:一个是以Go语言关键字命名,另一个刚好是以下划线和Go语言关键字命名,那么以Go语言关键字命名的成员将无法访问(被屏蔽)
数组、字符串和切片
CGO的C虚拟包提供了以下一组函数,用于Go语言和C语言之间数组和字符串的双向转换:
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byte
该组辅助函数都是以克隆的方式运行。
当Go语言字符串和切片向C语言转换时,克隆的内存由C语言的malloc函数分配,最终可以通过free函数释放。
当C语言字符串或数组向Go语言转换时,克隆的内存由Go语言分配管理。
如果不希望单独分配内存,可以在Go语言中直接访问C语言的内存空间:
/*
#include <string.h>
char arr[10];
char *s = "Hello";
*/
import "C"
import (
"reflect"
"unsafe"
)
func main() {
// 通过 reflect.SliceHeader 转换
var arr0 []byte
var arr0Hdr = (*reflect.SliceHeader)(unsafe.Pointer(&arr[0]))
arr0Hdr.Data = uintptr(unsafe.Pointer(&C.arr[0]))
arr0Hdr.Len = 10
arr0Hdr.Cap = 10
// 通过切片语法转换
arr1 := (*[31]byte)(unsafe.Pointer(&C.arr[0]))[:10:10]
var s0 string
var s0Hdr = (*reflect.StringHeader)(unsafe.Pointer(&s0))
s0Hdr.Data = uintptr(unsafe.Pointer(C.s))
s0Hdr.Len = int(C.strlen(C.s))
sLen := int(C.strlen(C.s))
s1 := string((*[31]byte)(unsafe.Pointer(C.s))[:sLen:sLen])
}
指针间的转换
cgo存在的一个目的就是打破Go语言的禁止,恢复C语言应有的指针的自由转换和指针运算。以下代码演示了如何将X类型的指针转化为Y类型的指针:
var p *X
var q *Y
q = (*Y)(unsafe.Pointer(p)) // *X => *Y
p = (*X)(unsafe.Pointer(q)) // *Y => *X
unsafe.Pointer指针类型类似C语言中的void*类型的指针。
任何类型的指针都可以通过强制转换为unsafe.Pointer指针类型去掉原有的类型信息,然后再重新赋予新的指针类型而达到指针间的转换的目的。
数值和指针的转换
Go语言针对unsafe.Pointr指针类型特别定义了一个uintptr类型。我们可以uintptr为中介,实现数值类型到unsafe.Pointr指针类型到转换。再结合前面提到的方法,就可以实现数值和指针的转换了。
切片间的转换
var p []X
var q []Y
pHdr := (*reflect.SliceHeader)(unsafe.Pointer(&p))
qHdr := (*reflect.SliceHeader)(unsafe.Pointer(&q))
pHdr.Data = qHdr.Data
pHdr.Len = qHdr.Len * unsafe.Sizeof(q[0]) / unsafe.Sizeof(p[0])
pHdr.Cap = qHdr.Cap * unsafe.Sizeof(q[0]) / unsafe.Sizeof(p[0])
函数调用
因为C语言不支持返回多个结果,因此<errno.h>标准库提供了一个errno宏用于返回错误状态。我们可以近似地将errno看成一个线程安全的全局变量,可以用于记录最近一次错误的状态码。
CGO也针对<errno.h>标准库的errno宏做的特殊支持:在CGO调用C函数时如果有两个返回值,那么第二个返回值将对应errno错误状态。此特性对于void类型函数依然有效。第一个返回值是C语言的void对应的Go语言类型:main._Ctype_void{}
其实在CGO生成的代码中,_Ctype_void类型对应一个0长的数组类型[0]byte
当导出C语言接口时,需要保证函数的参数和返回值类型都是C语言友好的类型,同时返回值不得直接或间接包含Go语言内存空间的指针。
内部机制
CGO特性主要是通过一个叫cgo的命令行工具来辅助输出Go和C之间的桥接代码。
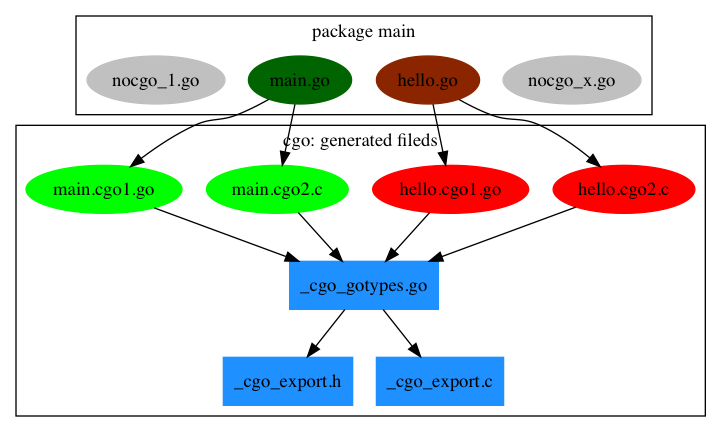
包中有4个Go文件,其中nocgo开头的文件中没有import “C”指令,其它的2个文件则包含了cgo代码。cgo命令会为每个包含了cgo代码的Go文件创建2个中间文件,比如 main.go 会分别创建 main.cgo1.go 和 main.cgo2.c 两个中间文件。然后会为整个包创建一个 _cgo_gotypes.go Go文件,其中包含Go语言部分辅助代码。此外还会创建一个 _cgo_export.h 和 _cgo_export.c 文件,对应Go语言导出到C语言的类型和函数。
Go调用C函数
package main
//int sum(int a, int b) { return a+b; }
import "C"
func main() {
println(C.sum(1, 1))
}
首先构建并运行该例子没有错误。然后通过cgo命令行工具在_obj目录生成中间文件:
$ go tool cgo main.go
查看_obj目录生成中间文件:
$ ls _obj | awk '{print $NF}'
_cgo_.o
_cgo_export.c
_cgo_export.h
_cgo_flags
_cgo_gotypes.go
_cgo_main.c
main.cgo1.go
main.cgo2.c
其中cgo.o、_cgo_flags和_cgo_main.c文件和我们的代码没有直接的逻辑关联,可以暂时忽略。
我们先查看main.cgo1.go文件,它是main.go文件展开虚拟C包相关函数和变量后的Go代码:
package main
//int sum(int a, int b) { return a+b; }
import _ "unsafe"
func main() {
println((_Cfunc_sum)(1, 1))
}
其中C.sum(1, 1)函数调用被替换成了(Cfunc_sum)(1, 1)。每一个C.xxx形式的函数都会被替换为_Cfunc_xxx格式的纯Go函数,其中前缀_Cfunc表示这是一个C函数,对应一个私有的Go桥接函数。
_Cfunc_sum函数在cgo生成的_cgo_gotypes.go文件中定义:
//go:cgo_unsafe_args
func _Cfunc_sum(p0 _Ctype_int, p1 _Ctype_int) (r1 _Ctype_int) {
_cgo_runtime_cgocall(_cgo_506f45f9fa85_Cfunc_sum, uintptr(unsafe.Pointer(&p0)))
if _Cgo_always_false {
_Cgo_use(p0)
_Cgo_use(p1)
}
return
}
_Cfunc_sum函数的参数和返回值_Ctype_int类型对应C.int类型,命名的规则和_Cfunc_xxx类似,不同的前缀用于区分函数和类型。
其中_cgo_runtime_cgocall对应runtime.cgocall函数,函数的声明如下:
func runtime.cgocall(fn, arg unsafe.Pointer) int32
第一个参数是C语言函数的地址,第二个参数是存放C语言函数对应的参数结构体的地址。
在这个例子中,被传入C语言函数_cgo_506f45f9fa85_Cfunc_sum也是cgo生成的中间函数。函数在main.cgo2.c定义:
void _cgo_506f45f9fa85_Cfunc_sum(void *v) {
struct {
int p0;
int p1;
int r;
char __pad12[4];
} __attribute__((__packed__)) *a = v;
char *stktop = _cgo_topofstack();
__typeof__(a->r) r;
_cgo_tsan_acquire();
r = sum(a->p0, a->p1);
_cgo_tsan_release();
a = (void*)((char*)a + (_cgo_topofstack() - stktop));
a->r = r;
}
这个函数参数只有一个void范型的指针,函数没有返回值。真实的sum函数的函数参数和返回值均通过唯一的参数指针类实现。
_cgo_506f45f9fa85_Cfunc_sum函数的指针指向的结构为:
struct {
int p0;
int p1;
int r;
char __pad12[4];
} __attribute__((__packed__)) *a = v;
其中p0成员对应sum的第一个参数,p1成员对应sum的第二个参数,r成员,__pad12用于填充结构体保证对齐CPU机器字的整倍数。
然后从参数指向的结构体获取调用参数后开始调用真实的C语言版sum函数,并且将返回值保持到结构体内返回值对应的成员。
因为Go语言和C语言有着不同的内存模型和函数调用规范。其中_cgo_topofstack函数相关的代码用于C函数调用后恢复调用栈。_cgo_tsan_acquire和_cgo_tsan_release则是用于扫描CGO相关的函数则是对CGO相关函数的指针做相关检查。
C.sum的整个调用流程图如下:

其中runtime.cgocall函数是实现Go语言到C语言函数跨界调用的关键。更详细的细节可以参考 https://golang.org/src/cmd/cgo/doc.go 内部的代码注释和 runtime.cgocall 函数的实现。
C调用Go函数
package main
//int sum(int a, int b);
import "C"
//export sum
func sum(a, b C.int) C.int {
return a + b
}
func main() {}
为了在C语言中使用sum函数,我们需要将Go代码编译为一个C静态库:
$ go build -buildmode=c-archive -o sum.a sum.go
如果没有错误的话,以上编译命令将生成一个sum.a静态库和sum.h头文件。其中sum.h头文件将包含sum函数的声明,静态库中将包含sum函数的实现。
要分析生成的C语言版sum函数的调用流程,同样需要分析cgo生成的中间文件:
$ go tool cgo main.go
_obj目录还是生成类似的中间文件。为了查看方便,我们刻意忽略了无关的几个文件:
$ ls _obj | awk '{print $NF}'
_cgo_export.c
_cgo_export.h
_cgo_gotypes.go
main.cgo1.go
main.cgo2.c
其中_cgo_export.h文件的内容和生成C静态库时产生的sum.h头文件是同一个文件,里面同样包含sum函数的声明。
既然C语言是主调用者,我们需要先从C语言版sum函数的实现开始分析。C语言版本的sum函数在生成的_cgo_export.c文件中(该文件包含的是Go语言导出函数对应的C语言函数实现):
int sum(int p0, int p1)
{
__SIZE_TYPE__ _cgo_ctxt = _cgo_wait_runtime_init_done();
struct {
int p0;
int p1;
int r0;
char __pad0[4];
} __attribute__((__packed__)) a;
a.p0 = p0;
a.p1 = p1;
_cgo_tsan_release();
crosscall2(_cgoexp_8313eaf44386_sum, &a, 16, _cgo_ctxt);
_cgo_tsan_acquire();
_cgo_release_context(_cgo_ctxt);
return a.r0;
}
sum函数的内容采用和前面类似的技术,将sum函数的参数和返回值打包到一个结构体中,然后通过runtime/cgo.crosscall2函数将结构体传给_cgoexp_8313eaf44386_sum函数执行。
runtime/cgo.crosscall2函数采用汇编语言实现,它对应的函数声明如下:
func runtime/cgo.crosscall2(
fn func(a unsafe.Pointer, n int32, ctxt uintptr),
a unsafe.Pointer, n int32,
ctxt uintptr,
)
其中关键的是fn和a,fn是中间代理函数的指针,a是对应调用参数和返回值的结构体指针。
中间的_cgoexp_8313eaf44386_sum代理函数在_cgo_gotypes.go文件:
func _cgoexp_8313eaf44386_sum(a unsafe.Pointer, n int32, ctxt uintptr) {
fn := _cgoexpwrap_8313eaf44386_sum
_cgo_runtime_cgocallback(**(**unsafe.Pointer)(unsafe.Pointer(&fn)), a, uintptr(n), ctxt);
}
func _cgoexpwrap_8313eaf44386_sum(p0 _Ctype_int, p1 _Ctype_int) (r0 _Ctype_int) {
return sum(p0, p1)
}
内部将sum的包装函数_cgoexpwrap_8313eaf44386_sum作为函数指针,然后由_cgo_runtime_cgocallback函数完成C语言到Go函数的回调工作。
_cgo_runtime_cgocallback函数对应runtime.cgocallback函数,函数的类型如下:
func runtime.cgocallback(fn, frame unsafe.Pointer, framesize, ctxt uintptr)
参数分别是函数指针,函数参数和返回值对应结构体的指针,函数调用帧大小和上下文参数。
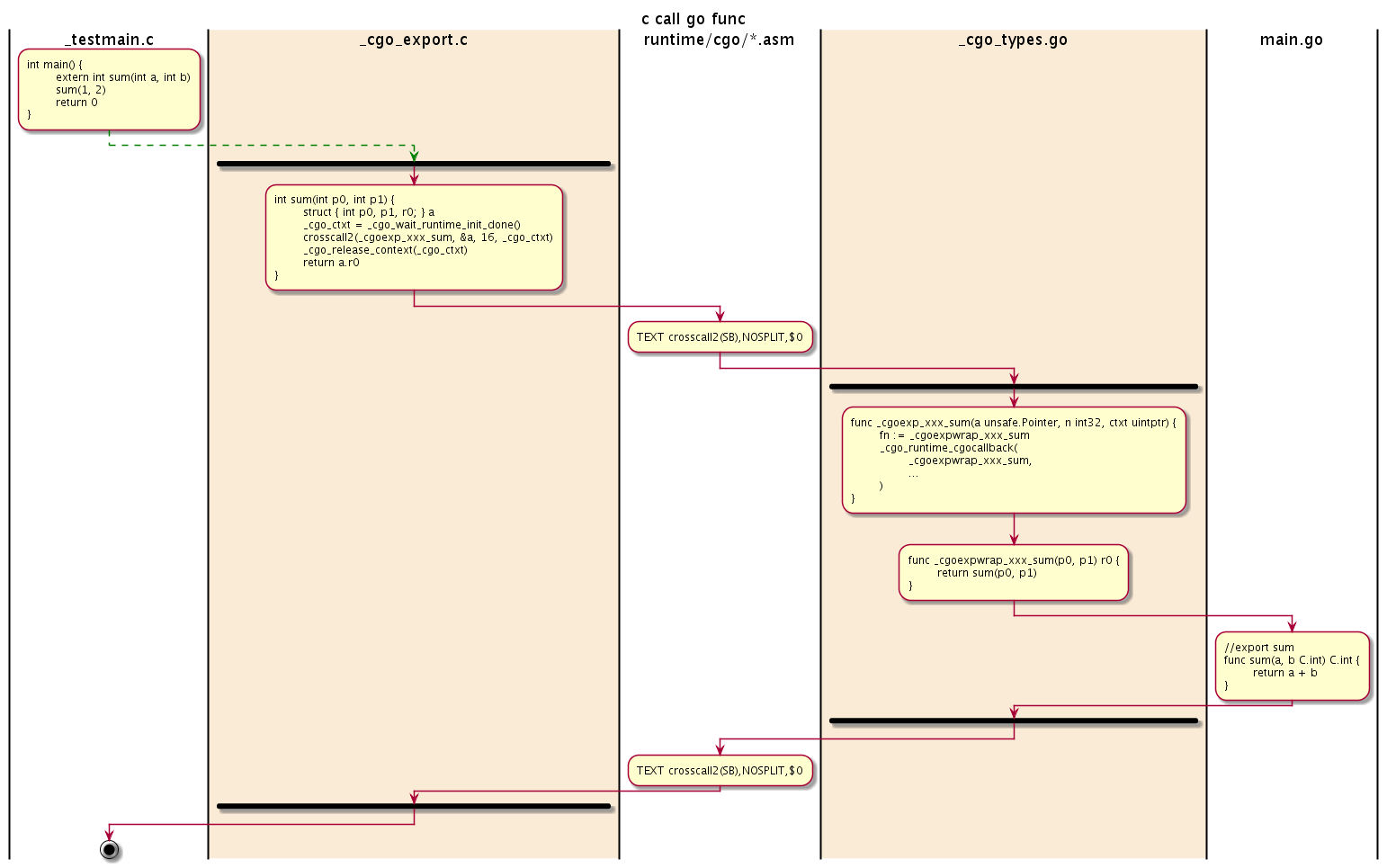
其中runtime.cgocallback函数是实现C语言到Go语言函数跨界调用的关键。更详细的细节可以参考相关函数的实现。
grpc
rpc
Go语言的RPC包的路径为net/rpc。
Go语言的RPC规则:方法只能有两个可序列化的参数,其中第二个参数是指针类型,并且返回一个error类型,同时必须是公开的方法。
客户端实现:
首选是通过rpc.Dial拨号RPC服务,然后通过client.Call调用具体的RPC方法。
func main() {
client, err := rpc.Dial("tcp", "localhost:1234")
if err != nil {
log.Fatal("dialing:", err)
}
var reply string
err = client.Call("HelloService.Hello", "hello", &reply)
if err != nil {
log.Fatal(err)
}
fmt.Println(reply)
}
在涉及RPC的应用中,作为开发人员一般至少有三种角色:
- 首选是服务端实现RPC方法的开发人员,
- 其次是客户端调用RPC方法的人员,
- 最后也是最重要的是制定服务端和客户端RPC接口规范的设计人员
我们将RPC服务的接口规范分为三个部分:
- 首先是服务的名字,
- 然后是服务要实现的详细方法列表,
- 最后是注册该类型服务的函数。
标准库的RPC默认采用Go语言特有的gob编码,因此从其它语言调用Go语言实现的RPC服务将比较困难。
Go语言的RPC框架有两个比较有特色的设计:
一个是RPC数据打包时可以通过插件实现自定义的编码和解码;
另一个是RPC建立在抽象的io.ReadWriteCloser接口之上的,我们可以将RPC架设在不同的通讯协议之上。
首先是基于json编码重新实现RPC服务:
func main() {
rpc.RegisterName("HelloService", new(HelloService))
listener, err := net.Listen("tcp", ":1234")
if err != nil {
log.Fatal("ListenTCP error:", err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Fatal("Accept error:", err)
}
go rpc.ServeCodec(jsonrpc.NewServerCodec(conn))
}
}
nc命令可以测试tcp
1. nc -l 1234 开启tcp服务
2. echo -e '{"method":"HelloService.Hello","params":["hello"],"id":1}' | nc localhost 1234 调用tcp服务
protobuf
Protobuf作为接口规范的描述语言,可以作为设计安全的跨语言PRC接口的基础工具。
在XML或JSON等数据描述语言中,一般通过成员的名字来绑定对应的数据。但是Protobuf编码却是通过成员的唯一编号来绑定对应的数据,因此Protobuf编码后数据的体积会比较小,但是也非常不便于人类查阅。
Protobuf的protoc编译器是通过插件机制实现对不同语言的支持。比如protoc命令出现–xxx_out格式的参数,那么protoc将首先查询是否有内置的xxx插件,如果没有内置的xxx插件那么将继续查询当前系统中是否存在protoc-gen-xxx命名的可执行程序,最终通过查询到的插件生成代码。对于Go语言的protoc-gen-go插件来说,里面又实现了一层静态插件系统。比如protoc-gen-go内置了一个gRPC插件,用户可以通过–go_out=plugins=grpc参数来生成gRPC相关代码,否则只会针对message生成相关代码。
参考gRPC插件的代码,可以发现generator.RegisterPlugin函数可以用来注册插件。插件是一个generator.Plugin接口:
// A Plugin provides functionality to add to the output during
// Go code generation, such as to produce RPC stubs.
type Plugin interface {
// Name identifies the plugin.
Name() string
// Init is called once after data structures are built but before
// code generation begins.
Init(g *Generator)
// Generate produces the code generated by the plugin for this file,
// except for the imports, by calling the generator's methods P, In,
// and Out.
Generate(file *FileDescriptor)
// GenerateImports produces the import declarations for this file.
// It is called after Generate.
GenerateImports(file *FileDescriptor)
}
grpc
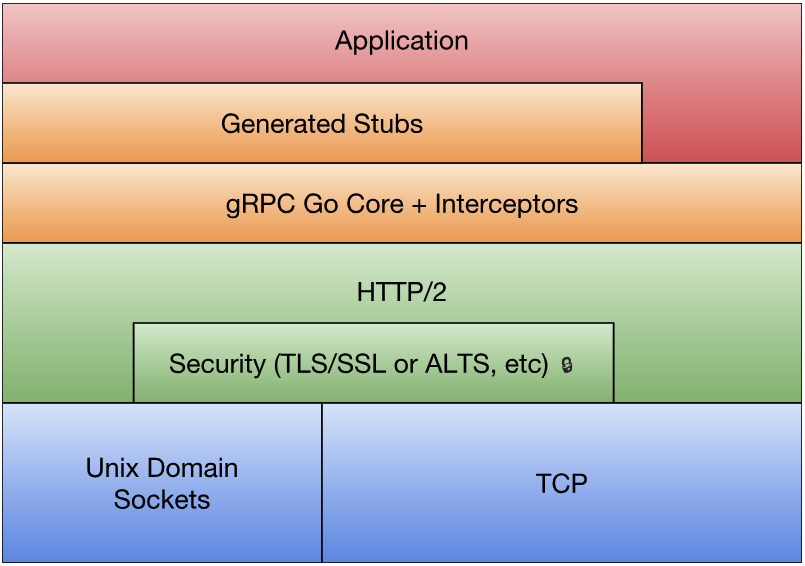
如果从Protobuf的角度看,gRPC只不过是一个针对service接口生成代码的生成器。
gRPC和标准库的RPC框架有一个区别,gRPC生成的接口并不支持异步调用。不过我们可以在多个Goroutine之间安全地共享gRPC底层的HTTP/2链接,因此可以通过在另一个Goroutine阻塞调用的方式模拟异步调用。
RPC是远程函数调用,因此每次调用的函数参数和返回值不能太大,否则将严重影响每次调用的响应时间。因此传统的RPC方法调用对于上传和下载较大数据量场景并不适合。同时传统RPC模式也不适用于对时间不确定的订阅和发布模式。为此,gRPC框架针对服务器端和客户端分别提供了流特性。
要实现对每个gRPC方法进行认证,需要实现grpc.PerRPCCredentials接口:
type PerRPCCredentials interface {
// GetRequestMetadata gets the current request metadata, refreshing
// tokens if required. This should be called by the transport layer on
// each request, and the data should be populated in headers or other
// context. If a status code is returned, it will be used as the status
// for the RPC. uri is the URI of the entry point for the request.
// When supported by the underlying implementation, ctx can be used for
// timeout and cancellation.
// TODO(zhaoq): Define the set of the qualified keys instead of leaving
// it as an arbitrary string.
GetRequestMetadata(ctx context.Context, uri ...string) (
map[string]string, error,
)
// RequireTransportSecurity indicates whether the credentials requires
// transport security.
RequireTransportSecurity() bool
}
在GetRequestMetadata方法中返回认证需要的必要信息。RequireTransportSecurity方法表示是否要求底层使用安全链接。在真实的环境中建议必须要求底层启用安全的链接,否则认证信息有泄露和被篡改的风险。
详细地认证工作主要在Authentication.Auth方法中完成。首先通过metadata.FromIncomingContext从ctx上下文中获取元信息,然后取出相应的认证信息进行认证。如果认证失败,则返回一个codes.Unauthenticated类型地错误。
gRPC中的grpc.UnaryInterceptor和grpc.StreamInterceptor分别对普通方法和流方法提供了截取器的支持。我们这里简单介绍普通方法的截取器用法。
要实现普通方法的截取器,需要为grpc.UnaryInterceptor的参数实现一个函数:
func filter(ctx context.Context,
req interface{}, info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler,
) (resp interface{}, err error) {
log.Println("fileter:", info)
return handler(ctx, req)
}
函数的ctx和req参数就是每个普通的RPC方法的前两个参数。第三个info参数表示当前是对应的那个gRPC方法,第四个handler参数对应当前的gRPC方法函数。上面的函数中首先是日志输出info参数,然后调用handler对应的gRPC方法函数。
要使用filter截取器函数,只需要在启动gRPC服务时作为参数输入即可:
server := grpc.NewServer(grpc.UnaryInterceptor(filter))
gRPC构建在HTTP/2协议之上,因此我们可以将gRPC服务和普通的Web服务架设在同一个端口之上。
Protobuf扩展实现步骤
1. 定义扩展
2. 通过proto可以获取扩展信息
3. 写一个示例
4. 以示例为基础定义plugin, 生成template
5. 生成插件。通过插件解析proto文件,生成代码。
reflection包中只有一个Register函数,用于将grpc.Server注册到反射服务中。
grpcurl是Go语言开源社区开发的工具, go get github.com/fullstorydev/grpcurl
grpcurl中最常使用的是list命令,用于获取服务或服务方法的列表。比如grpcurl localhost:1234 list命令将获取本地1234端口上的grpc服务的列表。
go web编程
router
较流行的开源go Web框架大多使用httprouter,或是基于httprouter的变种对路由进行支持。
httprouter和众多衍生router使用的数据结构被称为压缩字典树(Radix Tree)。读者可能没有接触过压缩字典树,但对字典树(Trie Tree)应该有所耳闻。图 5-1是一个典型的字典树结构:
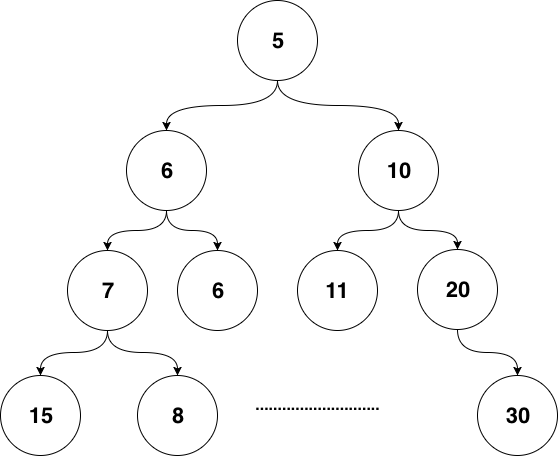
Trie树的2个操作:
1. 将字符串集合构造成Trie树
2. 在Trie树种查询一个字符串
Trie树性能高,以空间换时间。但是费内存,适合字符集小,前缀重复多的场景。
典型的压缩字典树结构:
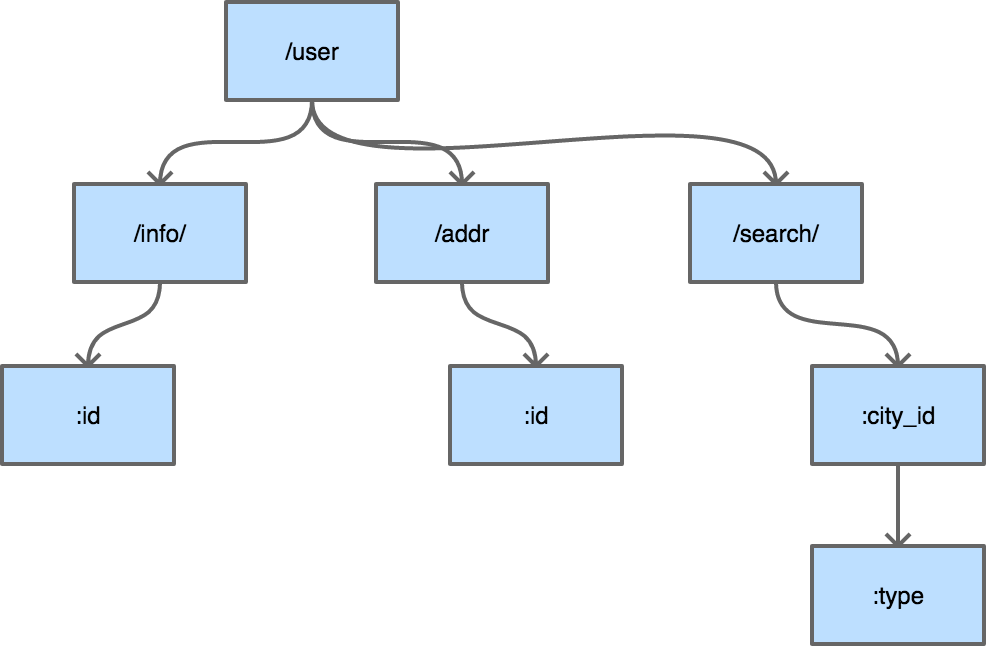
中间件
web中的中间件是指用来剥离业务代码和非业务代码的一种技术。
通过函数链的方式调用。
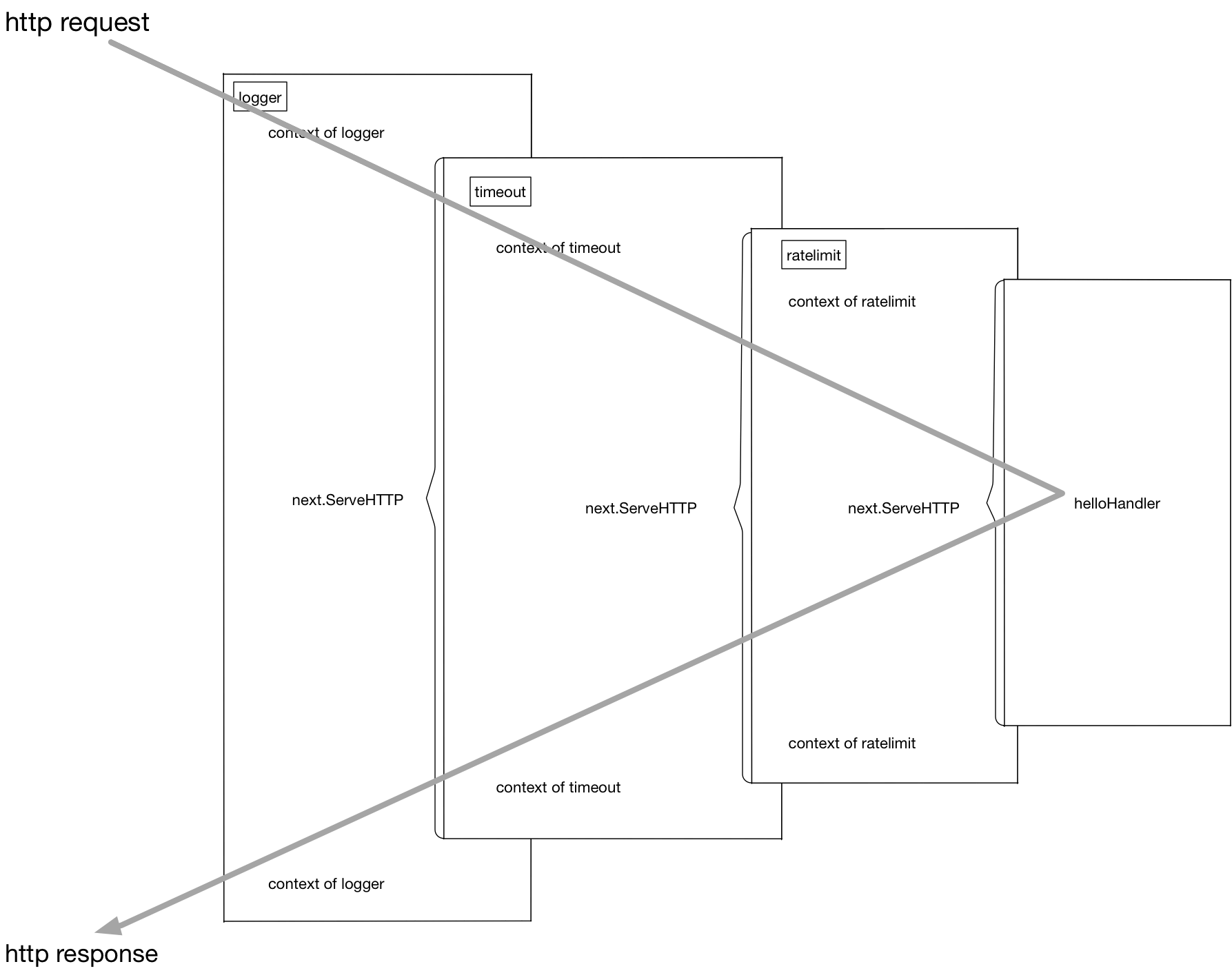
更一般的中间件切入点:
- 全局执行前
- 业务函数执行前
- 业务函数
- 业务函数执行后
- 全局执行后
每个切入点都可以支持多个,故一般都是以数组存储。
请求校验
请求校验,一般都不手写,而是通过定义Tag规则,代码反射出Tag信息,根据Tag校验。
现成的框架有validator.v9,如果要显示中文信息,需要其他包,示例代码
package main
import (
"fmt"
"github.com/go-playground/locales/zh"
"github.com/go-playground/universal-translator"
"gopkg.in/go-playground/validator.v9"
zh_translations "gopkg.in/go-playground/validator.v9/translations/zh"
)
type UserInfo struct {
FirstName string `validate:"required"`
LastName string `validate:"required"`
Age uint8 `validate:"gte=0,lte=100"`
Email string `validate:"required,email"`
}
func main() {
//中文翻译器
zh_ch := zh.New()
uni := ut.New(zh_ch)
trans, _ := uni.GetTranslator("zh")
//验证器
validate := validator.New()
//验证器注册翻译器
zh_translations.RegisterDefaultTranslations(validate, trans)
user := &UserInfo{
FirstName: "Badger",
LastName: "Smith",
Age: 105,
Email: "",
}
err := validate.Struct(user)
if err != nil {
for _, err := range err.(validator.ValidationErrors) {
//翻译错误信息
fmt.Println(err.Translate(trans))
}
return
}
fmt.Println("success")
}
输出:
Age必须小于或等于100
Email为必填字段
运行时反射会影响程序性能,如果要求更高性能,可以考虑把运行时代码变更成代码生成器,只是每次修改结构,都需要跑下生成器代码。
sql
执行sql的几个方法
| 方式 | 说简明 |
|---|---|
| ORM | 屏蔽sql底层细节的同时,隐藏了实现细节 |
| sql builder | 简单的sql拼装 |
| 定义sql语句 | 方便审核,java中有 mybatis |
限流
程序一般有3类瓶颈:
1. I/O瓶颈,磁盘问题
2. CPU密集计算型
3. 网络
web开发一般是网络端的。
压力测试工具: ab,wrk
限流的2类方式:
| 方式 | 说明 |
|---|---|
| 漏桶 | 固定的速率 |
| 令牌桶 | 允许一定的并发,用的较多 |
实际上,用不着真的放/取令牌,完全可以计算出来。譬如github.com/juju/ratelimit
灰度发布
灰度发布的2类形式:
- 分批次部署
- 通过业务规则
求哈希可用的算法非常多,比如md5,crc32,sha1等等,但我们这里的目的只是为了给这些数据做个映射,并不想要因为计算哈希消耗过多的cpu,所以现在业界使用较多的算法是murmurhash。
分布式
分布式id生成器
Twitter的snowflake算法是这种场景下的一个典型解法。先来看看snowflake是怎么一回事。
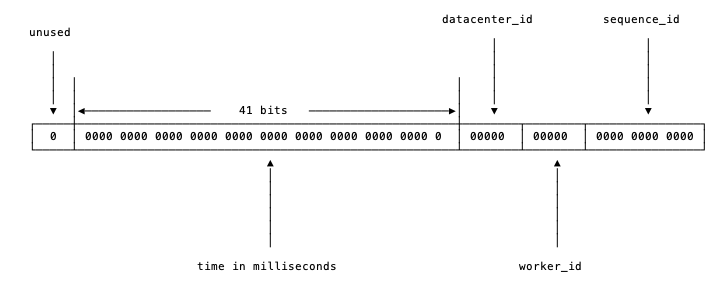
首先确定我们的数值是64位,int64类型,被划分为四部分,不含开头的第一个bit,因为这个bit是符号位。用41位来表示收到请求时的时间戳,单位为毫秒,然后五位来表示数据中心的id,然后再五位来表示机器的实例id,最后是12位的循环自增id(到达1111,1111,1111后会归0)。
这样的机制可以支持我们在同一台机器上,同一毫秒内产生2 ^ 12 = 4096条消息。一秒共409.6万条消息。从值域上来讲完全够用了。
数据中心加上实例id共有10位,可以支持我们每数据中心部署32台机器,所有数据中心共1024台实例。
表示timestamp的41位,可以支持我们使用69年。当然,我们的时间毫秒计数不会真的从1970年开始记,那样我们的系统跑到2039/9/7 23:47:35就不能用了,所以这里的timestamp实际上只是相对于某个时间的增量,比如我们的系统上线是2018-08-01,那么我们可以把这个timestamp当作是从2018-08-01 00:00:00.000的偏移量。
snowflake 是一个相当轻量化的snowflake的Go实现。
sonyflake是Sony公司的一个开源项目,基本思路和snowflake差不多,不过位分配上稍有不同,

这里的时间只用了39个bit,但时间的单位变成了10ms,所以理论上比41位表示的时间还要久(174年)。
分布式锁
| 锁 | 适应范围 | 优点 | 缺点 |
|---|---|---|---|
| sync.Mutex | 单机 | 都能完成 | |
| try-lock 通过channel可以实现 | 单机 | 单一任务,抢占式,抢不到就失败退出 | 费CPU,浪费在抢锁上 |
| redis/setnx | 集群 | 集群版的try-lock | 精度不高,可能丢数据 |
| zookeeper/Lock | 集群 | 集群版的mutex, 精度高 | 低吞吐量,搞延时 |
| etcd/Lock | 集群 | 同上 | 同上 |
延时任务系统
定时器(timer)的实现在工业界已经是有解的问题了。常见的就是时间堆和时间轮。
时间堆
最常见的时间堆一般用小顶堆实现,小顶堆其实就是一种特殊的二叉树,见图
小顶堆的好处是什么呢?实际上对于定时器来说,如果堆顶元素比当前的时间还要大,那么说明堆内所有元素都比当前时间大。进而说明这个时刻我们还没有必要对时间堆进行任何处理。定时检查的时间复杂度是O(1)。
当我们发现堆顶的元素小于当前时间时,那么说明可能已经有一批事件已经开始过期了,这时进行正常的弹出和堆调整操作就好。每一次堆调整的时间复杂度都是O(LgN)。
Go自身的内置定时器就是用时间堆来实现的,不过并没有使用二叉堆,而是使用了扁平一些的四叉堆。
时间轮
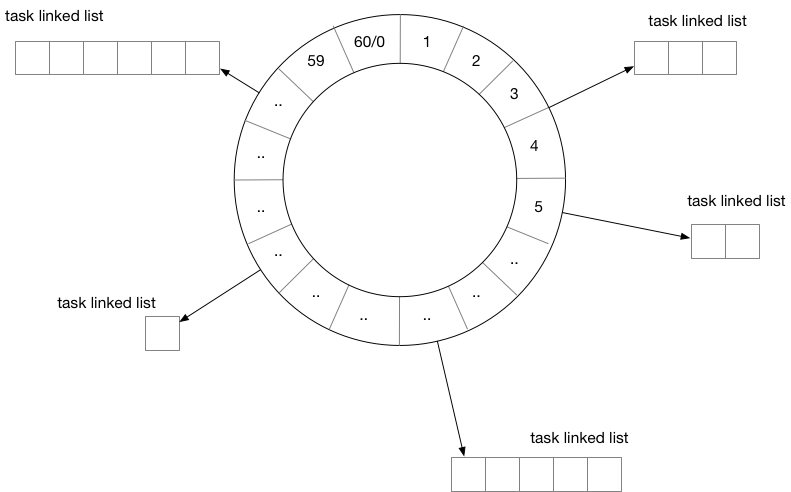
分布式搜索引擎
数据同步
在实际应用中,我们很少直接向搜索引擎中写入数据。更为常见的方式是,将MySQL或其它关系型数据中的数据同步到搜索引擎中。而搜索引擎的使用方只能对数据进行查询,无法进行修改和删除。
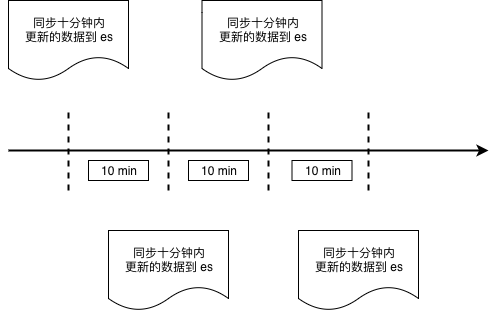
通过时间戳进行增量数据同步
通过 binlog 进行数据同步
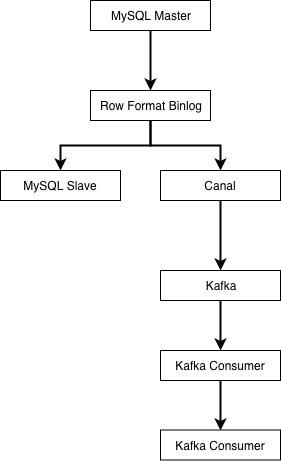
业界使用较多的是阿里开源的Canal,来进行binlog解析与同步。canal会伪装成MySQL的从库,然后解析好行格式的binlog,再以更容易解析的格式(例如json)发送到消息队列。
负载均衡
如果我们不考虑均衡的话,现在有n个服务节点,我们完成业务流程实际上只需要从这n个中挑出其中的一个。有几种思路:
按顺序挑: 例如上次选了第一台,那么这次就选第二台,下次第三台,如果已经到了最后一台,那么下一次从第一台开始。这种情况下我们可以把服务节点信息都存储在数组中,每次请求完成下游之后,将一个索引后移即可。在移到尽头时再移回数组开头处。
随机挑一个: 每次都随机挑,真随机伪随机均可。假设选择第 x 台机器,那么x可描述为rand.Intn()%n。
根据某种权重,对下游节点进行排序,选择权重最大/小的那一个。
基于洗牌算法的负载均衡
// 重点在这个 shuffle
func shuffle(slice []int) {
for i := 0; i < len(slice); i++ {
a := rand.Intn(len(slice))
b := rand.Intn(len(slice))
slice[a], slice[b] = slice[b], slice[a]
}
}
假设每次挑选都是真随机,我们假设第一个位置的节点在len(slice)次交换中都不被选中的概率是((6/7)*(6/7))^7 ≈ 0.34。而分布均匀的情况下,我们肯定希望被第一个元素在任意位置上分布的概率均等,所以其被随机选到的概率应该约等于1/7≈0.14。
显然,这里给出的洗牌算法对于任意位置的元素来说,有30%的概率不对其进行交换操作。所以所有元素都倾向于留在原来的位置。因为我们每次对shuffle数组输入的都是同一个序列,所以第一个元素有更大的概率会被选中。在负载均衡的场景下,也就意味着节点数组中的第一台机器负载会比其它机器高不少(这里至少是3倍以上)。
修正洗牌算法
从数学上得到过证明的还是经典的fisher-yates算法,主要思路为每次随机挑选一个值,放在数组末尾。然后在n-1个元素的数组中再随机挑选一个值,放在数组末尾,以此类推。
func shuffle(indexes []int) {
for i:=len(indexes); i>0; i-- {
lastIdx := i - 1
idx := rand.Intn(i)
indexes[lastIdx], indexes[idx] = indexes[idx], indexes[lastIdx]
}
}
在Go的标准库中实际上已经为我们内置了该算法:
func shuffle(n int) []int {
b := rand.Perm(n)
return b
}
配置管理
可以用etcd
分布式爬虫
colly单机爬虫 + nats消息队列 = 分布式爬虫
About The Author
bjmayor
程序员,码农,php,python,ios,android,go,产品经理,创业。